AI-Ready DevOps: How to Build Scalable Infrastructure Beyond AI Pilots
Learn how to implement AI-ready DevOps with AIOps, observability, and governance to deploy AI systems in production without increasing risk. Discover how to improve decision reliability, reduce alert noise, and introduce automation with control and auditability.

Why AI-Ready DevOps Is Now a Business Imperative
Traditional enterprise DevOps was designed for deterministic systems, where stable infrastructure and disciplined processes lead to predictable outcomes. In that model, observability data supports operational control.
AI systems break this assumption. Their outputs are probabilistic, context-dependent, and sensitive to data drift. As organizations add AI into production, telemetry volume explodes across logs, metrics, traces, and events.
The challenge is no longer data scarcity. It is signal scarcity inside data abundance.
For IT Operations and SRE teams, this pressure is immediate and continuous. They must triage alerts, correlate logs/metrics/traces across services, determine root causes, and coordinate remediation under strict uptime targets.
In AI-enabled environments, both incident volume and ambiguity increase: infrastructure can be healthy while model behavior still fails at the business layer. The result is:
-
Longer time to resolution
-
More alert fatigue
-
Slower operational decisions
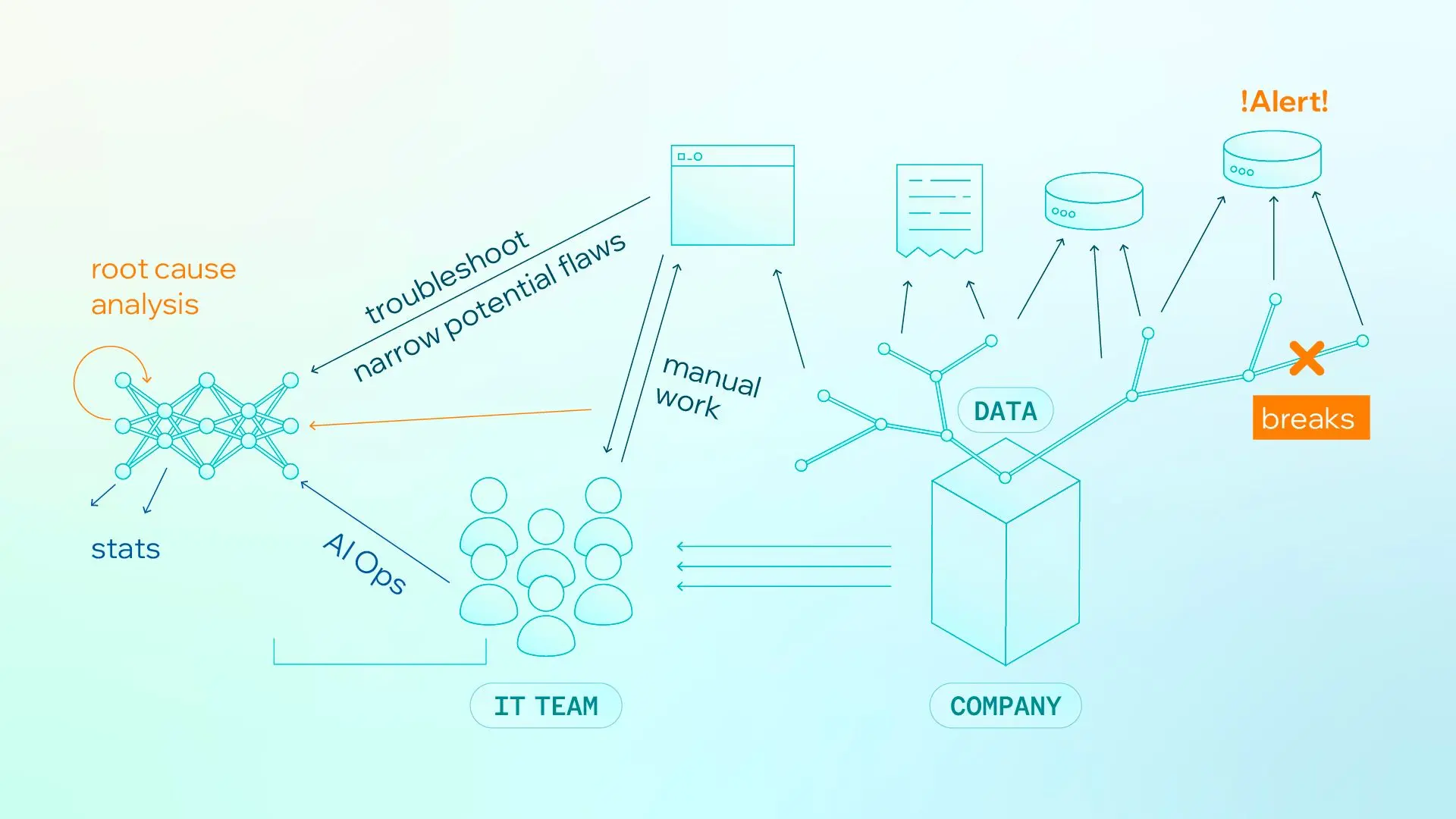
Figure 1. Manual operations under data overload create alert fatigue and slower root-cause resolution.
This exposes a fundamental gap in traditional DevOps: it does not account for AI decision quality. Traditional metrics such as latency, uptime, and error rate still matter, but they are no longer sufficient.
Modern AI-ready DevOps must therefore measure:
-
Accuracy and consistency
-
Hallucination rates
-
Model performance over time
-
Decision impact on business outcomes
Without this shift, AI remains stuck in isolated pilots. With it, organizations can build production-ready AI systems that scale safely, reliably, and with governance.
AIOps Must Start with Business Intent
At enterprise scale, AIOps cannot begin with tooling, but with business intent: which outcomes must improve, which risks must be reduced, and which service commitments must be protected. Without this alignment, even advanced platforms fail to produce measurable operational gains.
This requires design discipline. Teams need KPI frameworks and standardized templates that define what to collect and how to interpret it, including log and event schemas, dependency context, incident taxonomy, and response playbooks. With these in place, analytics can detect anomalies, correlate events, and prioritize likely root causes.
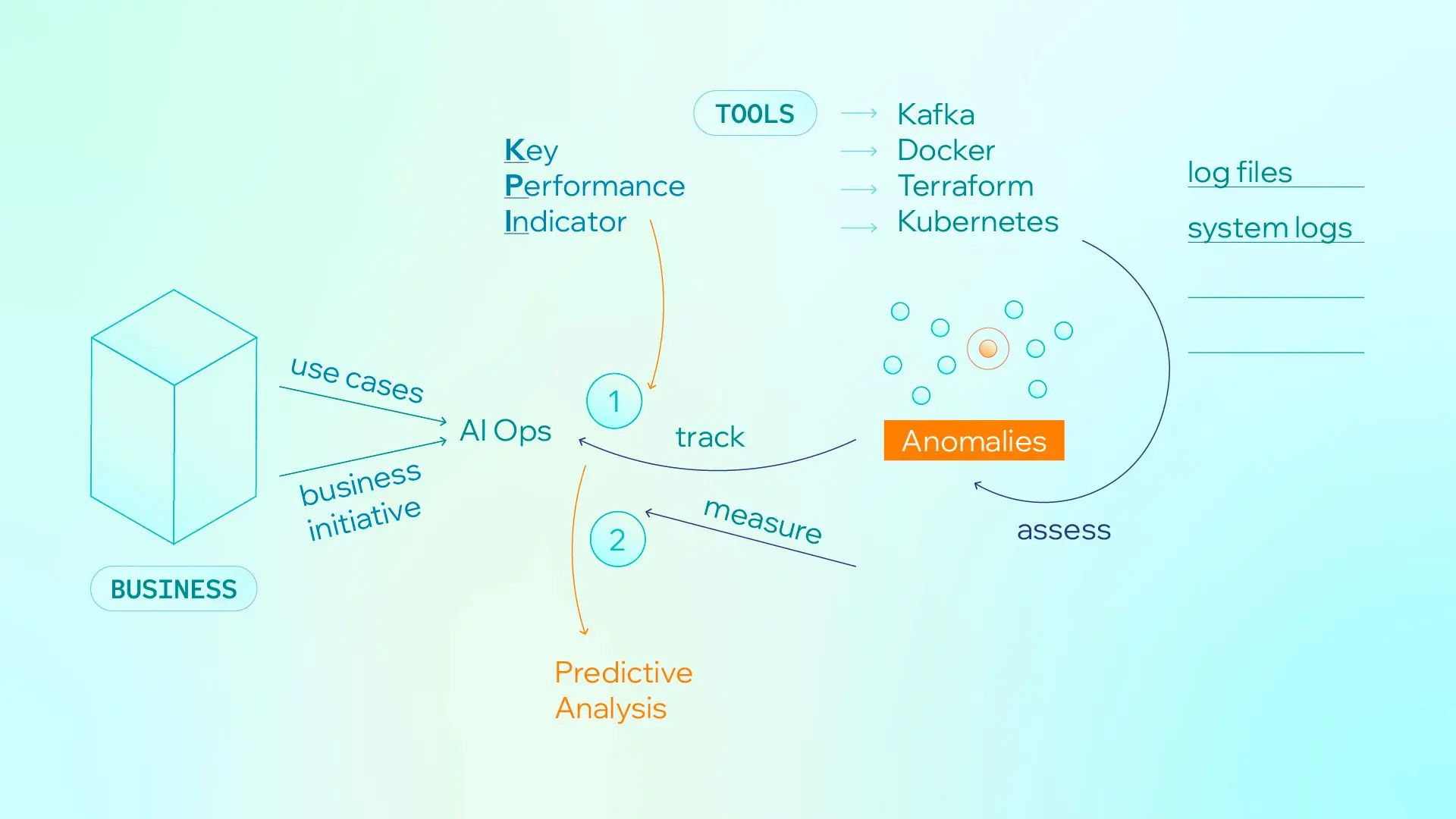
Figure 2. Business intent, KPI definition, and telemetry analysis form the foundation before automation.
Business initiatives define KPIs, telemetry is collected from core systems, and analytics generate predictive signals. Enterprises do not start from auto-remediation. They start from a structured understanding.
3 Pillars of AI-Ready Infrastructure
To lead this transition, leaders must align three domains into one operating flow: define outcomes, separate signal from noise, turn insight into action, and automate only when controls are proven.
1. Signal Foundation (What to Observe and Why)
AI systems require a rethinking of observability. Key components:
-
Business Goal to KPI Mapping: Translate outcomes into measurable reliability and decision-quality metrics.
-
Telemetry as a Product: Build structured logs, metrics, traces, and events with ownership, quality controls, and lineage.
-
Operational Context: Preserve dependencies, change history, and incident context so analysis reflects system reality.
The goal is to improve the signal-to-noise ratio in observability systems, enabling faster and more accurate diagnosis.
2. Decision Intelligence Layer (How to Diagnose and Decide)
Once high-quality signals exist, the next step is turning them into actionable insights. Core capabilities:
-
Detection and Correlation: Use anomaly detection, pattern recognition, and event correlation to narrow failure paths quickly.
-
Root-Cause Prioritization: Rank likely causes and recommend next actions to reduce manual triage.
-
Human-Guided Response: Use runbook recommendations and approval-based actions before full autonomy.
This layer reduces alert fatigue and accelerates AI system reliability in production.
3. Governance & Guardrails (How to Scale Safely)
At enterprise scale, governance must be embedded directly into the infrastructure to prevent production disruption while AI moves faster.
To manage this effectively, governance must define both what needs to be controlled and how those controls are enforced at runtime.
Governance Domains
-
Cost Management (FinOps): Monitoring token consumption and compute credits to prevent cost drift.
-
Security & Compliance: Managing prompt injection, data leakage, and policy enforcement risks.
-
Sovereignty Decisions: Choosing between third-party APIs and self-hosted open-source models based on risk, cost, and control.
Control Mechanisms
-
Policy Enforcement Points: Enforce policy at runtime for every agent action.
-
Action Registry: Maintain a controlled list of allowed actions, required permissions, and risk tiers.
-
Least-Privilege IAM: Scope each agent role to minimal required access, with no wildcard privileges.
-
Mandatory Auditability: Record request, decision, execution, and outcome for every action.
-
Escalation Workflow: Route high-risk or low-confidence actions to human review teams.
-
Kill Switch and Rollback: Limit blast radius with immediate stop and recovery mechanisms.
Every AI agent must operate within explicit action boundaries, mapped to approved scopes, and constrained by least-privilege access. High-impact actions require policy checks, audit trails, and rollback safeguards by default. When risk thresholds are exceeded, actions should escalate for human approval before execution.
Automate Last, not First
When these three pillars are aligned, automation can be introduced safely as the final layer: policy-bound, auditable, and outcome-driven. The operational outcomes are clear: lower MTTR, less alert noise, faster root-cause identification, and more reliable service performance at scale.
Automation is an execution layer, not a starting point. Without KPI alignment and decision validation, it scales noise instead of intelligence.
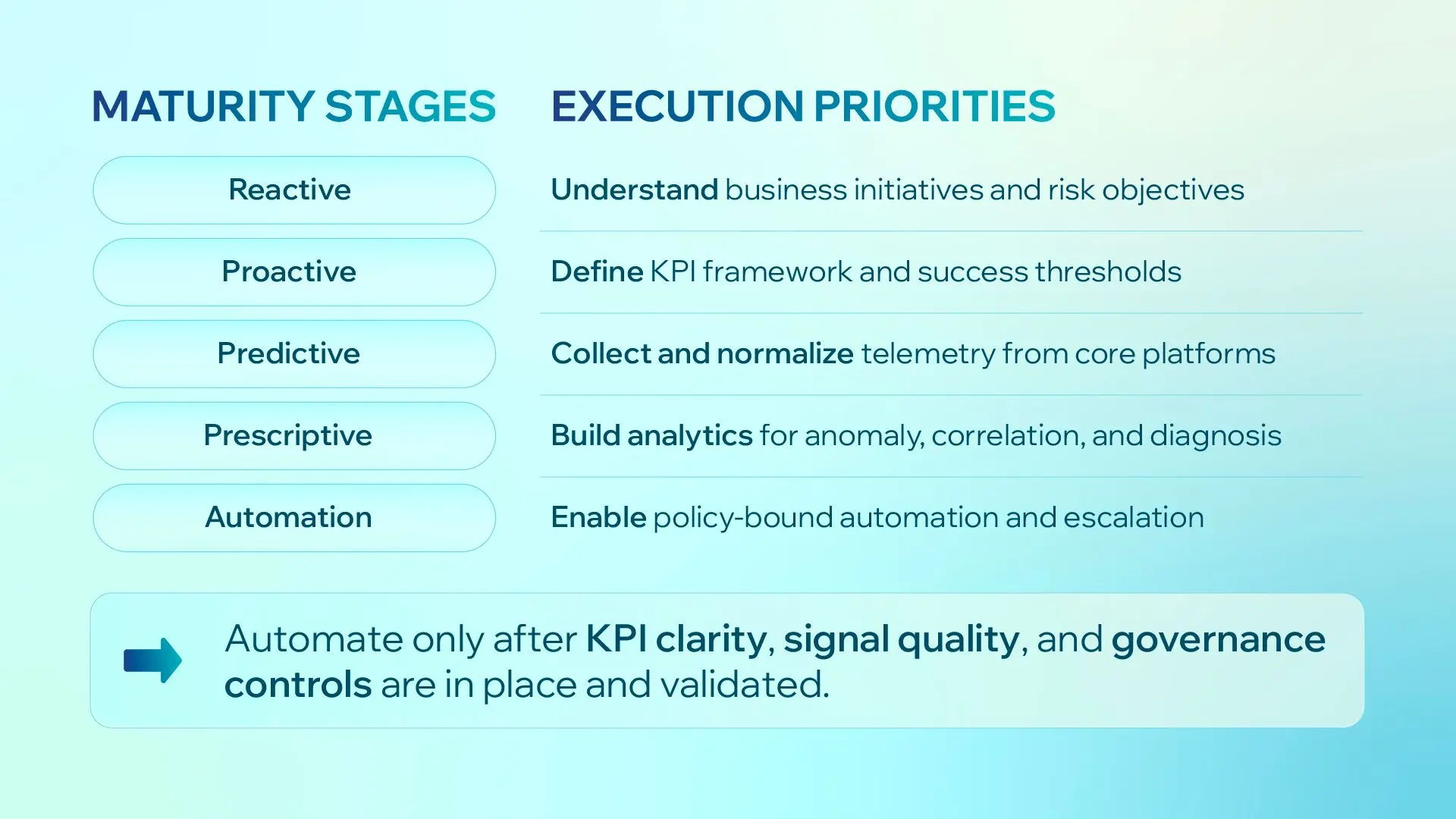
Figure 3. Enterprise AIOps maturity moves from reactive operations to controlled automation.
AI-Ready DevOps Operating Model
Technology alone does not deliver outcomes. AI-ready DevOps requires a redesigned operating model across people, process, and governance:
-
Human-in-the-Loop: AI supports detection and recommendations; humans keep control of high-impact decisions.
-
Clear Ownership: Define who owns KPIs, who approves risky actions, and who leads incident review.
-
Cross-Functional Teaming: Align DevOps, SRE, data, and AI teams under shared reliability outcomes.
-
Simple Escalation Rules: Low-risk actions can run automatically; high-risk actions must go to review teams.
-
Practical Upskilling: Train teams on observability analytics, AI reliability, and policy-aware incident response.
Bottom line: AIOps culture is not about replacing operators. It is about making decisions faster, safer, and more consistent at scale.
AIOps Maturity Model
Maturity should be staged. Each phase must prove value before moving to the next.
| Phase | Focus | Key Outcome |
|---|---|---|
| Phase 1: Visibility | Align business goals, KPI baselines, and telemetry quality | A shared definition of success and a reliable operational baseline. |
| Phase 2: Intelligence | Add anomaly detection, event correlation, and root-cause prioritization | Faster diagnosis, lower alert noise, and reduced manual triage. |
| Phase 3: Automation with Guardrails | Introduce policy-bound automation and human-approved escalation for high-risk actions | Lower MTTR and scalable operations without governance loss. |
Conclusion: The Competitive Advantage
AI-ready DevOps is an operating model redesign, not simply a tooling refresh.
The winners in enterprise AI will not be the teams that automate first. They will be the teams that measure first, build intelligence on top of reliable signals, and automate with clear guardrails.

Giang Le
DevOps Engineer
Giang Le is a DevOps Engineer with 2 years of experience in cloud computing and web application operations, specializing in Microsoft Azure and familiar with AWS. He has hands-on expertise in automating deployments and managing scalable infrastructure using Docker, Kubernetes, and Infrastructure as Code tools such as Terraform and Pulumi (TypeScript).






