Unlocking AI for Your Business with the ML Engineering Process
Delve into crafting an effective strategy by assessing the relevance of AI and ML for your business. Gain practical insights from the Tanoto Project, offering valuable lessons on integrating artificial intelligence and machine learning into your applications/solutions through the ML engineering process.

Machine Learning (ML) and Artificial Intelligence (AI) are rapidly growing fields that combine the principles of computer science, statistics, and mathematics. While they are powerful tools for solving complex problems, they aren’t very effective when used in isolation. By integrating ML/AI with software engineering, developers can create practical applications that solve real-world problems.
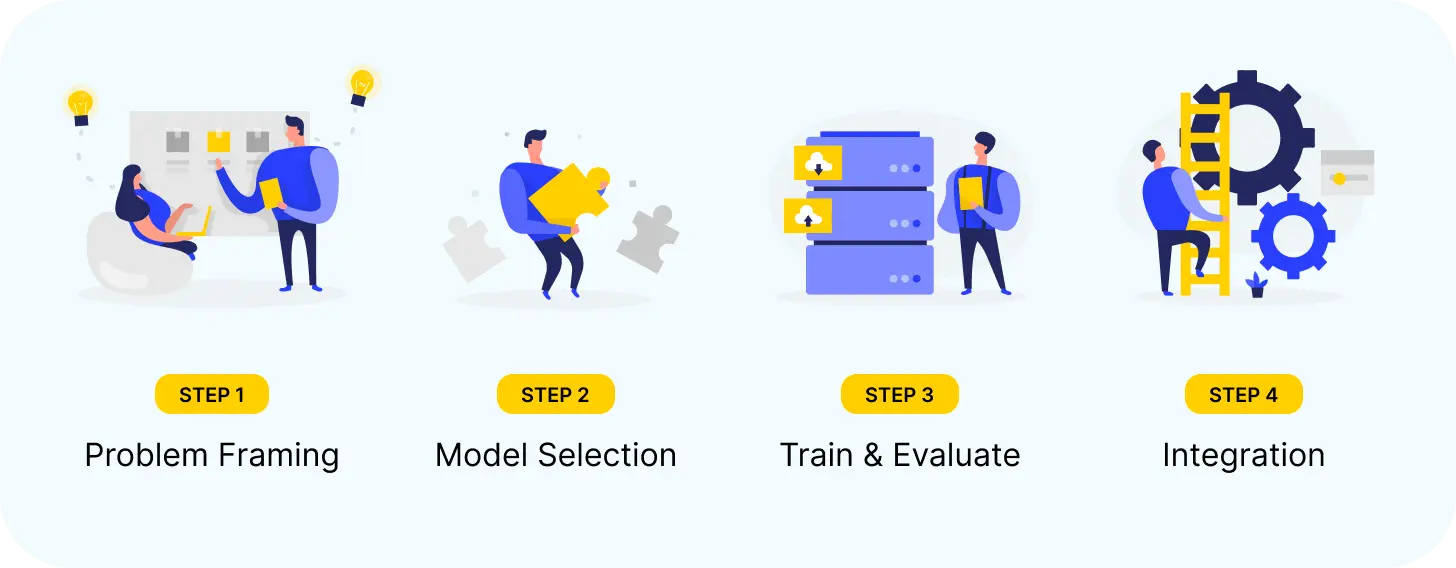
In this blog post, we will go over the steps of the ML engineering process: problem framing, model selection, training and evaluation, and integration.
Drawing parallels with our Tanoto project, where we employed various ML/AI techniques to simulate job interviews, we’ll highlight the specific features of face detection and emotion recognition in Tanoto as examples.
Problem framing
Effective problem framing is crucial for addressing challenges successfully and determining if ML is the appropriate solution. While some may view ML as a catch-all solution, it's important to recognize that it's most useful when applied to specific types of problems. By thoroughly defining the problem, we can avoid spending time and resources into overly complex ML solutions that don't deliver the desired results.
Problem framing in ML involves breaking down a problem to identify the specific elements that need attention. This includes defining the inputs, outputs, solution parameters, and the methods required to address the problem effectively.
By doing so, we can set clear goals and evaluate the technical feasibility of a potential ML project. A well-defined problem frame ensures the ML solution aligns with the desired outcome, ultimately leading to a successful product.
Typically, this means translating business requirements, with AI applications in mind, into technical ones. This allows a Machine learning engineer to devise actionable action steps for solution implementation. This is an interactive process between the ML engineer and the rest of the product team.
Tanoto example:
-
Business requirements: Non-verbal expressions during communication are as significant as spoken words. Our Job Interview simulator application (Tanoto) has access to the user’s webcam feed. We want to make recommendations and advice based on the emotions displayed in facial expressions during the interview.
-
Technical requirements:
- Input: A frame of the webcam feed showing the user’s face.
- Output: An emotion label.
- Approach: A square box containing a single face is extracted from the webcam frame using face detection and segmentation. This is then fed into an image classifier to determine an emotion label.
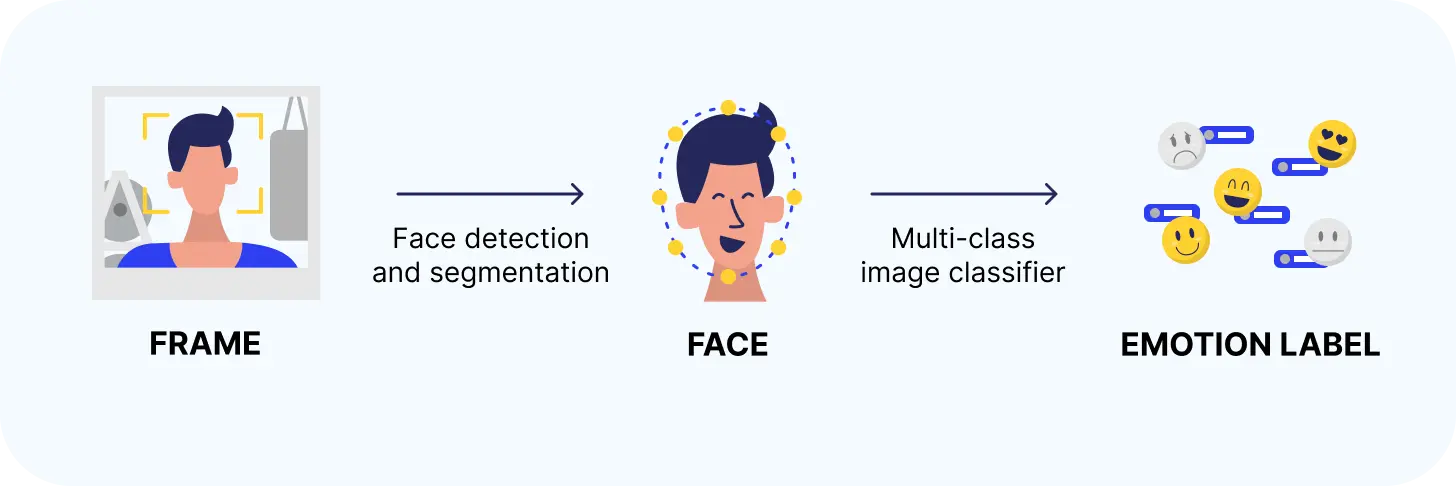
- Training data: A dataset of faces with annotated labels for emotions.
- Solution parameters: Considerations include the amount of data required, acceptable latency, computational power needs, cost justification, model deployment, and data privacy concerns.
Data and model selection
For common tasks, good models may already be trained and available
For many standard machine learning tasks (i.e., image classification, object detection, natural language processing), there are often pre-trained models readily available. Such models, having been trained on large datasets, offer robust performance and can be quickly integrated into your project. Utilizing pre-trained models can save considerable time and resources over training your own models from scratch.
However, for niche or domain-specific problems, suitable pre-trained models might not be available. In this case, you'll need to collect and label your own data to train your models. This can be a time-consuming and resource-intensive process, but it's necessary to achieve good performance.
Public and well-benchmarked datasets are the best
When collecting data for your own dataset, prioritize public and well-benchmarked ones. These datasets have undergone thorough testing and evaluation by the machine learning community, and they provide a reliable basis for comparing and evaluating model performance. Well-benchmarked datasets ensure your model’s performance is competitive.
Domain-specific tasks usually require building your own dataset
While public datasets are ideal for many applications, some domains require custom datasets tailored to specific needs. For example, if you're working on a medical diagnosis tool, you may need to collect data from medical imaging devices or patient records. In cases like this, building your own dataset from scratch is challenging but necessary to achieve good performance.
Following well-researched ML architectures and techniques saves time and ensures success
With many different machine learning architectures and techniques to choose from, it can be difficult to know which ones are most suitable. Follow well-researched architectures and techniques to save time and reduce the risk of selecting a suboptimal approach. Additionally, well-researched architectures and techniques are extensively tested and evaluated, ensuring your model will perform well in practice.
For components like pretrained models and library implementation, make sure support for your target platform is available
When selecting pre-trained models or machine learning libraries, ensure compatibility with your target platform. This includes both software and hardware considerations. Given that different models and libraries might come with different software dependencies or be written in different programming languages and frameworks, it's crucial to confirm their seamless integration with your existing software setup.
Moreover, various models and libraries may have diverse hardware requirements and capabilities (i.e., GPU acceleration, mixed precision, float quantization). It's vital to confirm their efficiency on your chosen hardware infrastructure. By ensuring compatibility, potential deployment problems can be avoided, promising optimal performance in production.
Tanoto example
- Face detection: Tensorflow JS implementation of MediaPipe face detection.
- Emotion recognition:
- Data: FER2013 (Facial Expression Recognition 2013 Dataset).
- Model: VGG16 for feature extraction + Multi-layer Perceptron for classification head.
- Platform support: Tensorflow JS supports running converted Tensorflow model checkpoints on the web.
Train and evaluate your model for ML Engineering
This part of the ML engineering process uses tried and tested steps to ensure the delivery of accurate predictions and drive real-world results.
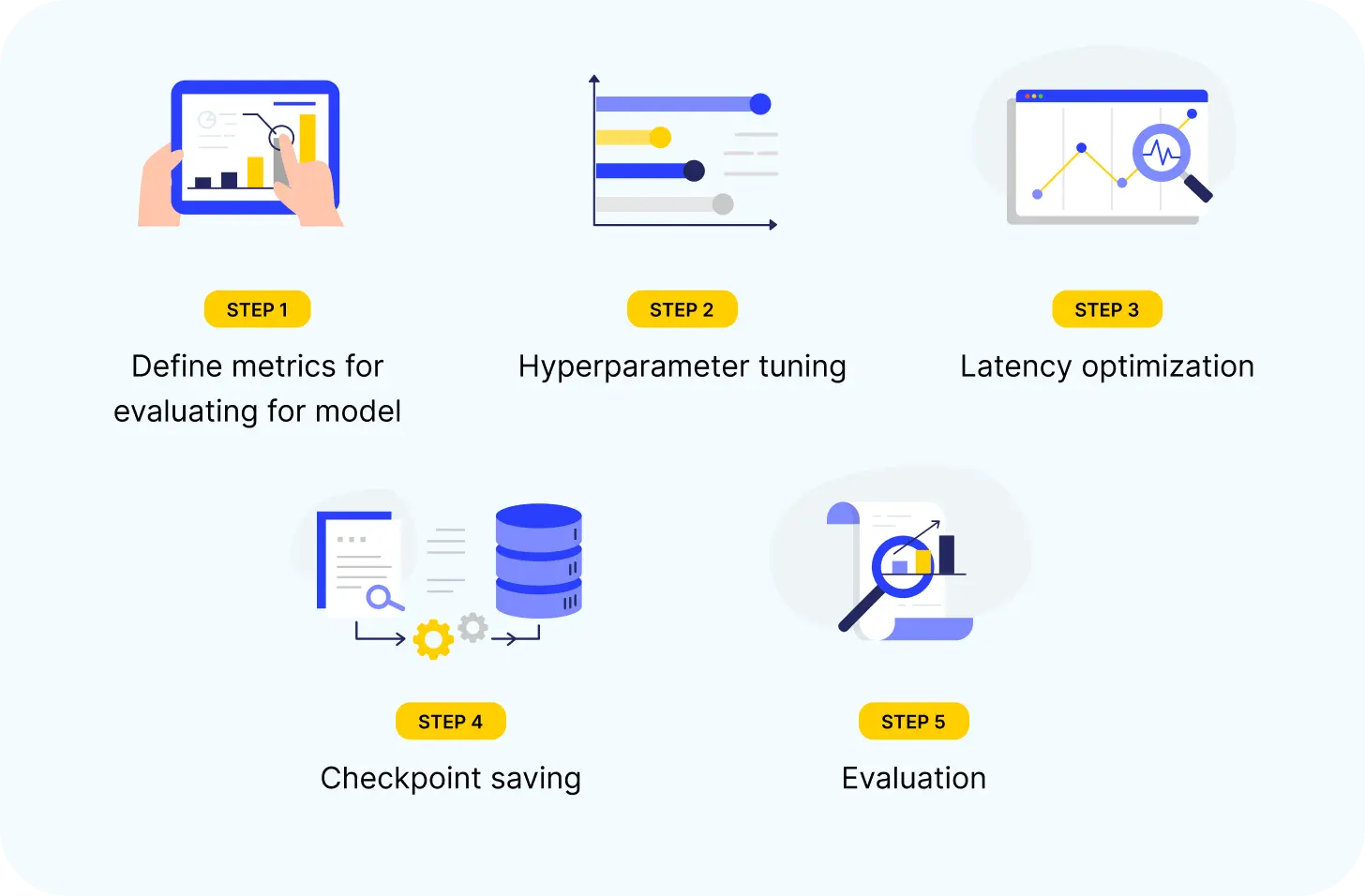
Define evaluation metrics:
- Use metrics relevant to your problem to measure model performance, such as accuracy, precision, recall, F1 score, etc.
- Tasks like image generation or voice synthesis, which require qualitative assessment, benefit greatly from human feedback.
- Compare your model’s performance against a baseline on the validation set, if applicable.
Hyperparameter tuning:
- Identify key hyperparameters that could impact model performance (i.e.,learning rate, batch size, number of hidden layers, regularization strength, etc.).
- Use a grid search or random search strategy to iterate through a range of values for each hyperparameter.
- Evaluate model performance on the validation set after each iteration; then, record the best combination of hyperparameters found.
- Consider using techniques like early stopping or callbacks to automatically stop training when the model's performance on the validation set starts to degrade.
Latency optimization:
- Measure the inference time (i.e., the time it takes to make predictions on new data) for your model on a representative dataset.
- Identify bottlenecks in the model that could be optimized for faster inference times, such as computationally expensive operations or large neural network layers.
- Implement techniques like quantization, pruning, or knowledge distillation to reduce the model’s computational cost of the model without significantly impacting its accuracy.
- Repeat the measurement and optimization steps until the desired inference time is achieved.
Checkpoint saving:
- Save the trained model weights and associated metadata (i.e., hyperparameters, training settings) at regular intervals during training.
- Store the checkpoints in a durable storage location (i.e., cloud storage service, distributed file system).
- Use a version control system or ML-specific tracking tool like WanDB to track model performance changes across experiments and enable collaboration.
Evaluation:
- Perform a final evaluation of your model on a separate test set (if you didn’t during hyperparameters tuning).
- Compare your model’s performance to state-of-the-art results, if applicable.
- Discuss model limitations and suggest directions for future improvements.
- If multiple model candidates were in consideration, a decision on a single model should be made at this step.
- Visualize evaluation results and comparison with tools like Matplotlib, Seaborn, and MATLAB, if possible, to enable effective communication of model performance.
By following these steps, you can rigorously train and evaluate your machine learning model, ensuring that it performs well and generalizes effectively to new data.
Integration
Collaboration among ML and non-ML engineers, designers, QA, DevOps
Collaboration is crucial when integrating machine learning models into bigger, existing systems. For example, a machine learning model may be used to classify images; but, it needs to be integrated with a front-end application that allows extracting frames from a user’s webcam feed, just like Tanoto.
- Non-ML engineers can implement infrastructure needed to support the model(i.e., data pipelines, data stores, and serving systems).
- Designers can create user interfaces that allow users to interact with or take advantage of the model.
- QA engineers can ensure the model behaves correctly and produces accurate results.
- DevOps engineers can automate model deployment and monitoring.
Connect expected input and output
Machine learning models typically operate on numerical data represented as matrices; however, the input and output data may not always be in a format convenient for non-ML team members. For example, image data may need to be processed to extract features that can be fed into a convolutional neural network. Similarly, text data may need to be tokenized and embedded before it can be fed into a natural language processing model.
To make the model more dev-friendly, it's necessary to perform input and output processing. This may involve converting data from a relational database into a matrix, normalizing or standardizing data, or transforming output data back into a format meaningful to non-ML members.
Carefully document the input and output processing steps to help non-ML team members understand what is happening to the data. This can help avoid misunderstandings and errors that might arise from miscommunication.
Document your model
- Documenting a machine learning model is essential for several reasons. First, it helps non-ML team members can understand how the model works and what assumptions were made during its development.
- A record of the model's architecture and parameters are provided, which can be useful for debugging purposes or recreating the model in the future.
- Ensure compliance with regulatory requirements, such as GDPR or CCPA, which require that organizations be transparent about how personal data is being used.
When documenting a model, it's important to strike a balance between simplicity and completeness. A high-level overview of the model's architecture and main components may be sufficient for non-ML team members who just want to understand the overall structure. Model inputs and outputs are critical details to include. However, for ML engineers and researchers who want to reproduce or extend the model, lower-level details such as hyperparameter tuning, regularization methods, and optimization algorithms may also be necessary.
In addition to documenting the model itself, it's also important to record the model’s training data, as well as any preprocessing or feature engineering steps that were performed. This information can help ensure that the model is reproducible and that its performance can be verified.
Monitoring
Monitoring a machine learning model is critical to ensure it continues to perform well over time, with several aspects to monitor (.e., data quality, model performance, deployment issues).
Model accuracy and reliability are affected by data quality, so make sure to monitor several factors (i.e., data distribution, missing values, outliers, and correlations between features).
Model performance should also be regularly monitored. It's important to detect any degradation in model performance early on, so corrective action can be quickly taken. Typical causes for model performance decreasing over time include data drift and concept drift. Data drift happens when the distribution of model training data changes over time. Concept drift occurs when the properties of what the model is trying to predict changes.
For example, during COVID-19, non-medical news articles used many medical terms, which would confuse news topic classification models that were trained on pre-pandemic data. This can be remedied by continuous retraining as new data comes in and enough time has passed, or there has been a major shift in the real world that affects the factors around the problem.
Deployment issues can range from hardware failures to software bugs. Monitoring can help quickly identify issues quickly and minimize downtime.
For a more detailed look at deployment, scaling and cost optimization for running ML models, head over to one of our popular blogs: Cost-optimized ML on Production: Autoscaling GPU Nodes on Kubernetes to Zero Using KEDA.
Conclusion
In summary, the ML engineering process, which encompasses problem definition, model selection, training and evaluation, and integration, is a roadmap for developers to turn their ideas into reality. By harnessing the power of ML and AI, we can create cutting-edge applications that transform industries and improve people's lives.
Given the rapid evolution of ML/AI and ML engineering, it’s important to remain adaptable when it comes to best practices and standard processes. For now, happy experimenting and coding, and don’t forget to watch out for future ML/AI-related blogs from CodeLink!
Tien Ha
Senior AI & Full-stack Developer
Tien Ha is an AI and Full-stack Developer with four years of experience. Specializing in Python, JavaScript, and modern frameworks, Tien excels in AI model design and developing scalable backend and frontend services, seamlessly integrating AI development with software engineering.



