Video Call with ChatGPT
Learn from our proof of concept that allows you to have a video call with ChatGPT. We added an avatar to the Large Language Model (LLM) to enable users to interact via chat on multiple topics.

OpenAI's ChatGPT is known for its advanced text-based interactions among the growing family of language learning models (LLMs). However, many UI clients for LLMs, including ChatGPT, are still text-based. We aimed to enhance this experience by adding an avatar to humanize LLMs and enabling voice interactions, which means you can have a video call with ChatGPT. Our goal is to give the LLM more personality and make conversations more enjoyable, although it already has a great personality!
To accomplish this task, we must integrate various models with LLM at the center. As LLM processes text input and generates text output, we must convert voice to text and vice versa for voice input and output to be possible. Specifically, we must:
- Utilize a speech-to-text model to transform user audio into text for LLM to process.
- Employ a text-to-speech model to transform LLM's text into audio to respond to the user.
- Synchronize the avatar with the audio output while incorporating additional head movements to create a realistic effect.
The outcome is this:
Diagram
The diagram below shows the structure of the application:
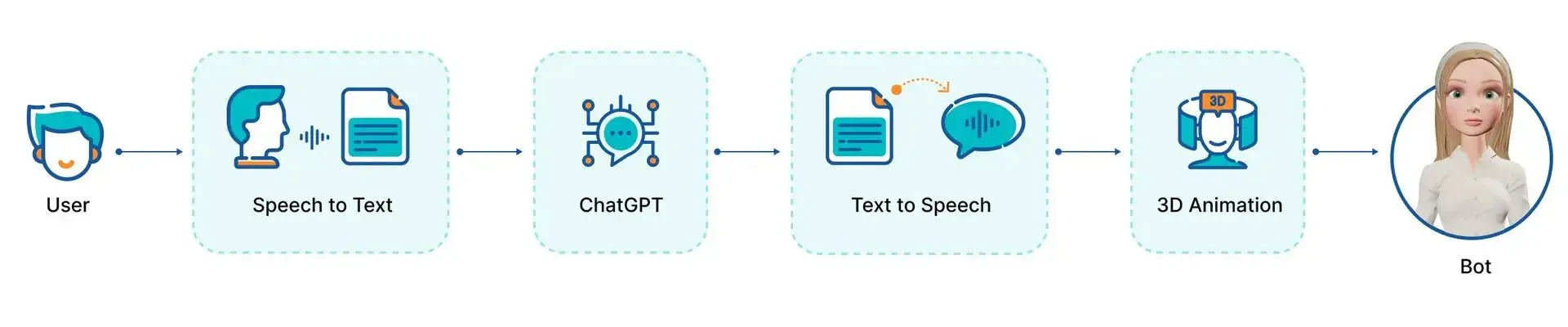
Techstack
In this Proof of Concept (PoC), we use several SaSS models and APIs, as well as open-source ones:
- ChatGPT as Language Model
- Azure Speech-to-Text
- Azure Text-to-Speech
- ThreeJS to animate the 3D model
3D face animation challenges
For 3D face animation, such as lip-syncing, eye blinking, and head tilting etc., there are two potential approaches:
A machine learning-based approach to generate a face from an image and text or audio. Several models can handle this, including:
- https://github.com/OpenTalker/SadTalker
- https://github.com/yerfor/GeneFace
- https://harlanhong.github.io/publications/dagan.html
Although generating a talking head from a single image (or several images) is impressive, and the output quality is convincing enough, these models are slow and difficult to make work in real-time on commercial devices.
3D-model approach: This approach enables us to control facial features such as lips, eyes, and head movements. To accomplish this, a 3D head model is required, which makes this approach less flexible. However, it guarantees real-time performance on most commercial devices. Visemes play a critical role in this approach as they represent the visual representation of phonemes in spoken language. By manipulating these visemes, we can synchronize the avatar's facial movements with the synthetic speech, resulting in a more realistic and engaging conversational experience. To achieve this, we needed the Text-to-Speech (TTS) model to provide 'blend shape' controls responsible for driving the facial movements of our 3D character. These blend shapes are represented as a 2-dimensional matrix where each row represents a frame, and each frame contains an array of 55 facial positions. Fortunately, the Azure TTS API conveniently returns this information for application to the 3D model.
We chose this approach because it allows for real-time rendering.
ChatGPT prompts
For this PoC, we utilized various prompts to simulate different roles, such as:
- An English teacher
- A ReactJS interviewer
- A Python interviewer
- A dream interpreter
- Phoebe Buffay (from Friends)
These prompts were sourced from the excellent repository found here, with minor adjustments made to fit our needs. The prompts were effectively executed to maintain each character's persona.
Open source alternatives
We used readily available SaSS services to build something quickly for the PoC. If you prefer open-source solutions, there are other options:
- Large Language Model: LlaMa, or stability AI LLM
- Speech to Text: Coqui STT, Whisper
- Text to Speech: Coqui TTS, ViTS. Note that this only returns audio, so you would need a phoneme-viseme model to generate blend shape controls for animating the 3D head.
Future development
We can enhance its capabilities using tools like LangChain, AutoGPT, or BabyAGI. For example, in the context of an English teacher, it can currently assist with correcting writing and grammar as well as providing feedback. By incorporating a speech analysis model, it can also offer feedback on pronunciation. Additionally, we can integrate the ability to search the internet and YouTube to suggest relevant lessons for further improving English skills.
KA Nguyen
Co-founder & CTO
As CodeLink's CTO, KA fosters innovation and personal development through curiosity-driven leadership. He excels in building and leading engineering teams, encouraging continuous learning and development. Currently, KA is developing machine learning models to address practical challenges, aiming to create impactful societal solutions. His leadership fosters a positive team environment marked by respect and collaboration.




