AI Agent Optimization: The Executive Guide to Predictable AI Agent Systems
Explore AI agent optimization strategies for building production-ready AI systems while maintaining performance, governance, and measurable business impact.
As enterprises move beyond the experimental phase of Agentic AI, the mandate for leadership has shifted from mere adoption to AI agent optimization to production-ready AI systems that are predictable, cost-effective, and scalable in real-world environments.
For leaders, optimization is a strategic necessity to prevent reliability ceilings, uncontrolled scaling risks, and spiralling token costs in LLM agent systems.
Agents in LLM Systems Exist on a Spectrum
In enterprise environments, AI agents are typically implemented across a range of AI agent architectures, reflecting different levels of autonomy, orchestration, and system complexity:
-
Retrieval Agents: A single LLM paired with relevant context.
-
Tool-Use Agents: An LLM equipped with specific executable functions or tool-calls.
-
Multi-Step Agents: A chain of LLMs utilizing controlled sub-agents to complete tasks.
-
Autonomous Agents: Systems like OpenClaw or Claude Code where LLMs operate in a continuous loop to solve open-ended problems.
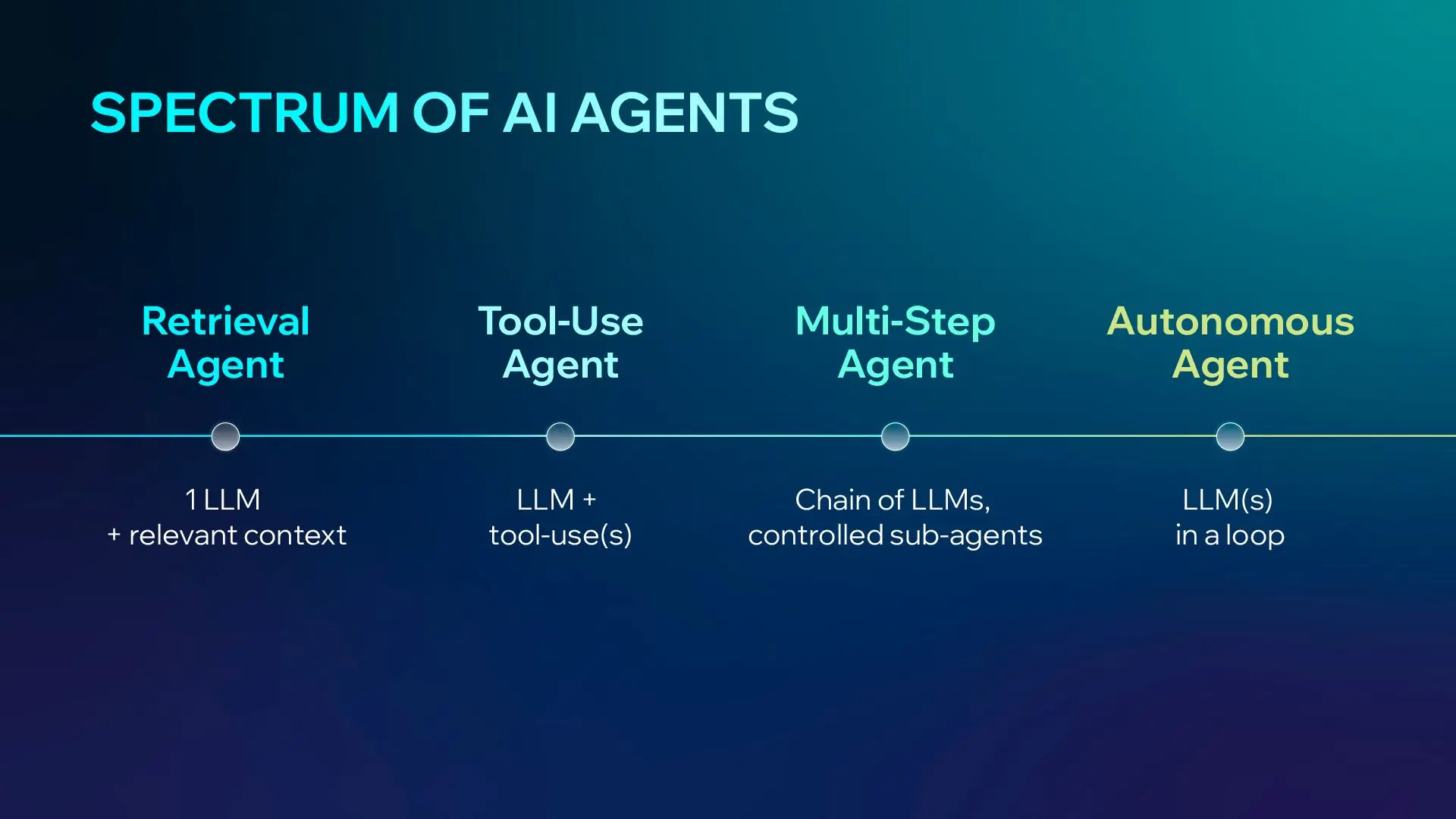
💡Reliability compounds downwards in autonomous and multi-agent systems architecture. A non-deterministic nature makes failures hard to predict and costs difficult to budget.
Core Trade-offs in AI Agent Optimization
The central challenge in building AI agents in production is the "Core Trade-off" triangle between Quality, Cost, and Speed (Latency):

Different architectural choices amplify different constraints:
-
Reasoning Models: Deliver better output quality but require significant trade-offs in both operational cost and processing speed.
-
Autonomous Loops: Maximize quality through iterative refinement, though this comes at the expense of exponentially higher token consumption.
-
Edge Models: Prioritize near-instant latency and minimal cost, typically sacrificing depth and complex reasoning quality.
-
Sub-agents: Balance high quality with optimized speed through parallel execution, though they introduce increased architectural complexity and hidden overhead.
For executives, this is not just an engineering trade-off. It directly impacts cost optimization for AI agents, system scalability, and user experience.
Making Agents Cheaper
Operational cost in LLM agent systems is driven by:
Cost = number of tokens × model type × number of agents
The primary driver of cost is model selection, followed by total token usage across the system.
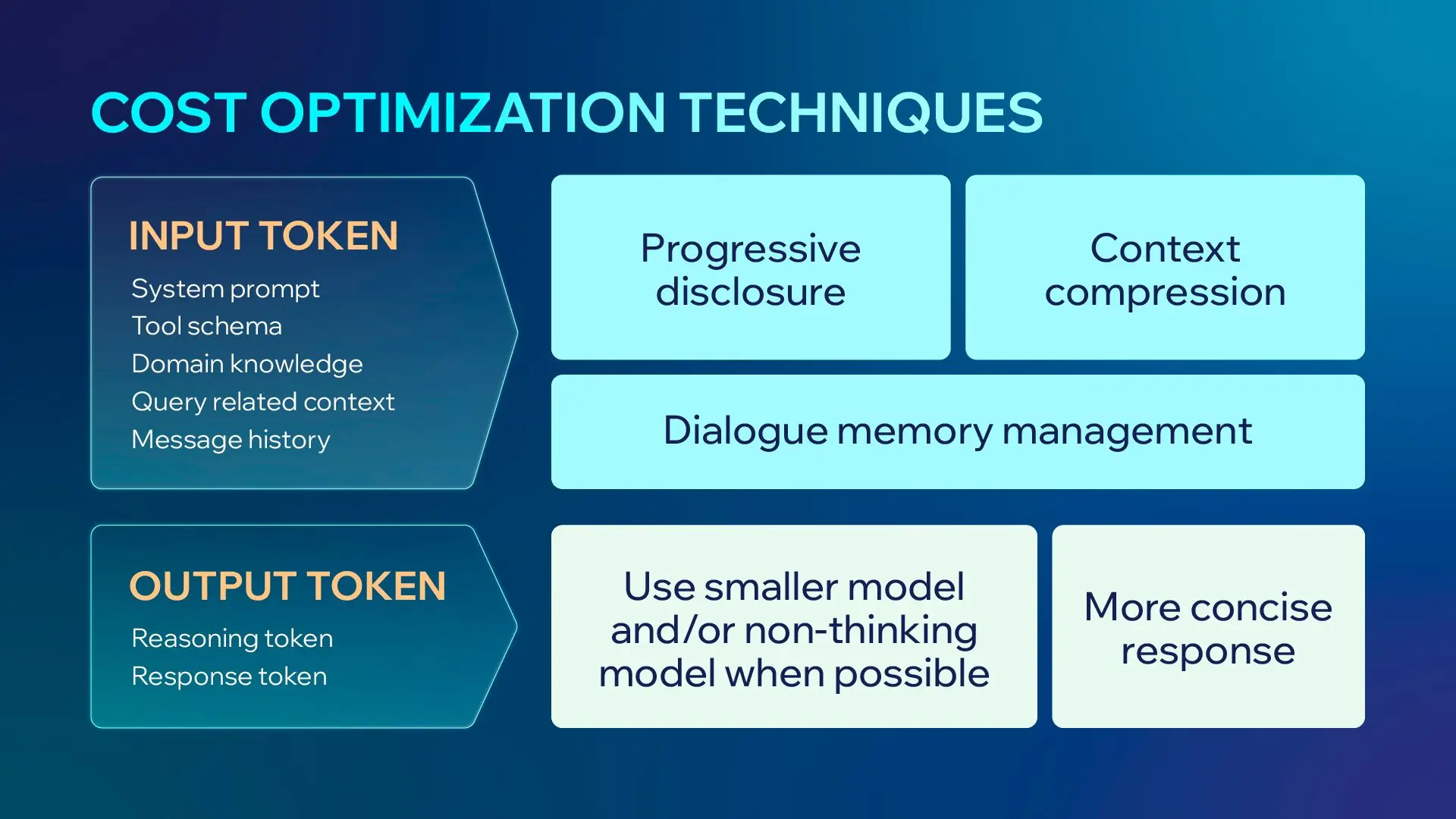
Practical Cost Optimization Techniques
Progressive Disclosure
In AI agent optimization, it means incrementally discovering relevant data through exploration rather than front-loading all possible information. This approach reduces token usage and improves system efficiency.
MCP (Model Context Protocol) is a strong example of this principle, enabling just-in-time context delivery rather than overloading the model upfront.
Dialogue Memory Management
Effective memory strategies are critical for AI agents in production, where long-running interactions can quickly inflate cost.
-
Sliding Window: This simple technique keeps only the last N turns and drops older messages. While cost-effective, it risks losing critical early context.
-
Recursive Summarization: Older turns are compressed into concise summaries while recent messages are kept verbatim. This maintains the gist of the conversation without the full token cost.
-
RAG-based Memory: Past dialogues are embedded and stored, allowing the agent to retrieve only semantically relevant turns on demand. This is the gold standard for maintaining long histories.
-
Hierarchical Memory: This multi-granularity approach keeps recent turns at full fidelity while older segments are progressively compressed into summaries.
-
Structured Note-taking: The agent maintains its own running state document (tracking facts, decisions, and progress) rather than replaying the full dialogue history.
All memory management techniques lead to smaller context windows, which significantly improve retrieval performance. However, because these methods are often lossy, teams should choose a technique based on their specific use case, acknowledging that some fine-grained detail may be sacrificed for architectural stability and cost-efficiency.
Making Agents Faster
Latency optimization is critical for production-ready AI systems, as it directly affects usability and adoption. This should be viewed across the entire pipeline, from request ingestion to token generation.
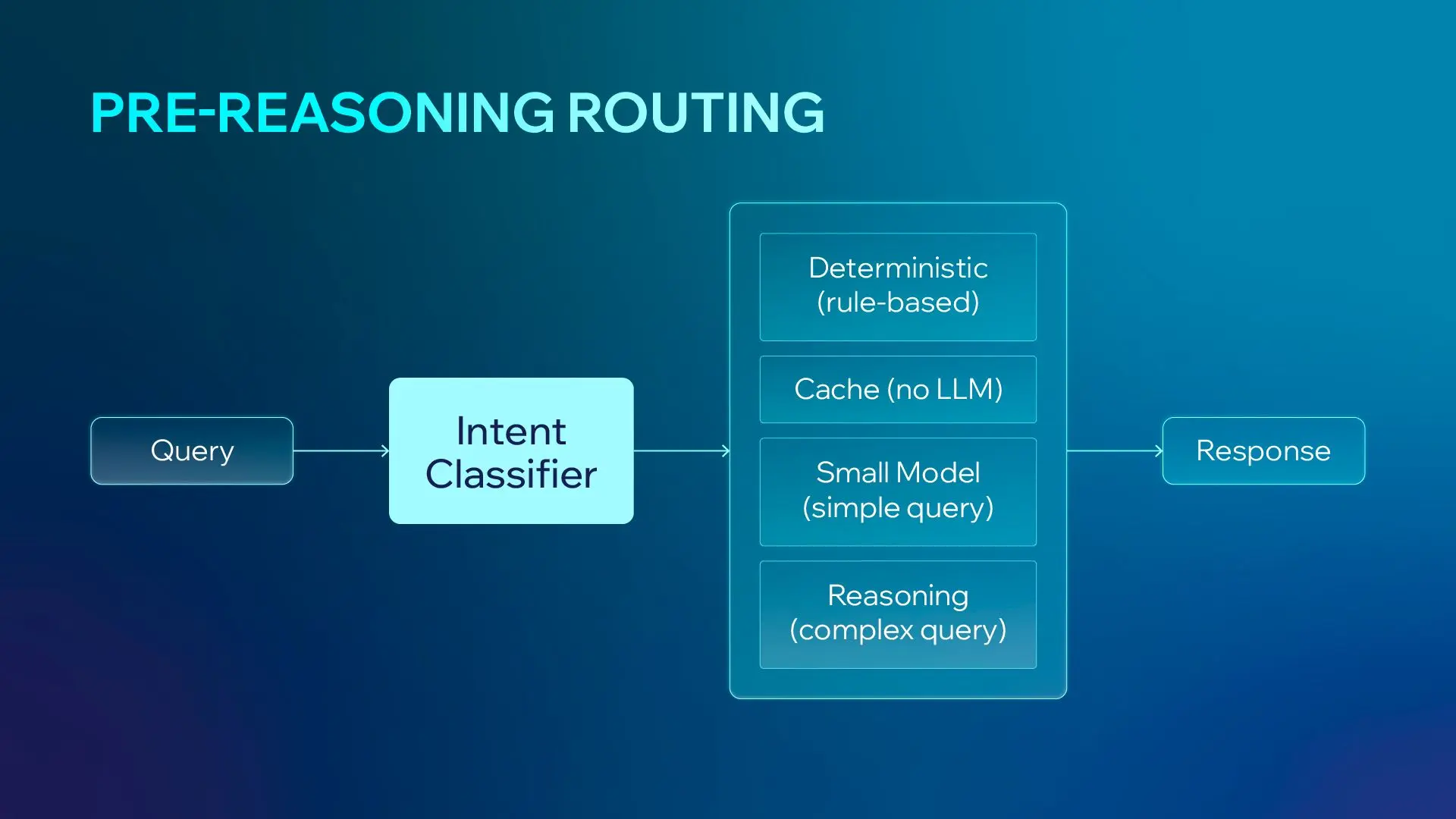
Pre-Reasoning Routing
Not every query requires a thinking model to do deep work and make no mistakes. By implementing an Intent Classifier, you can route simple queries to rule-based systems, caches, or small models.
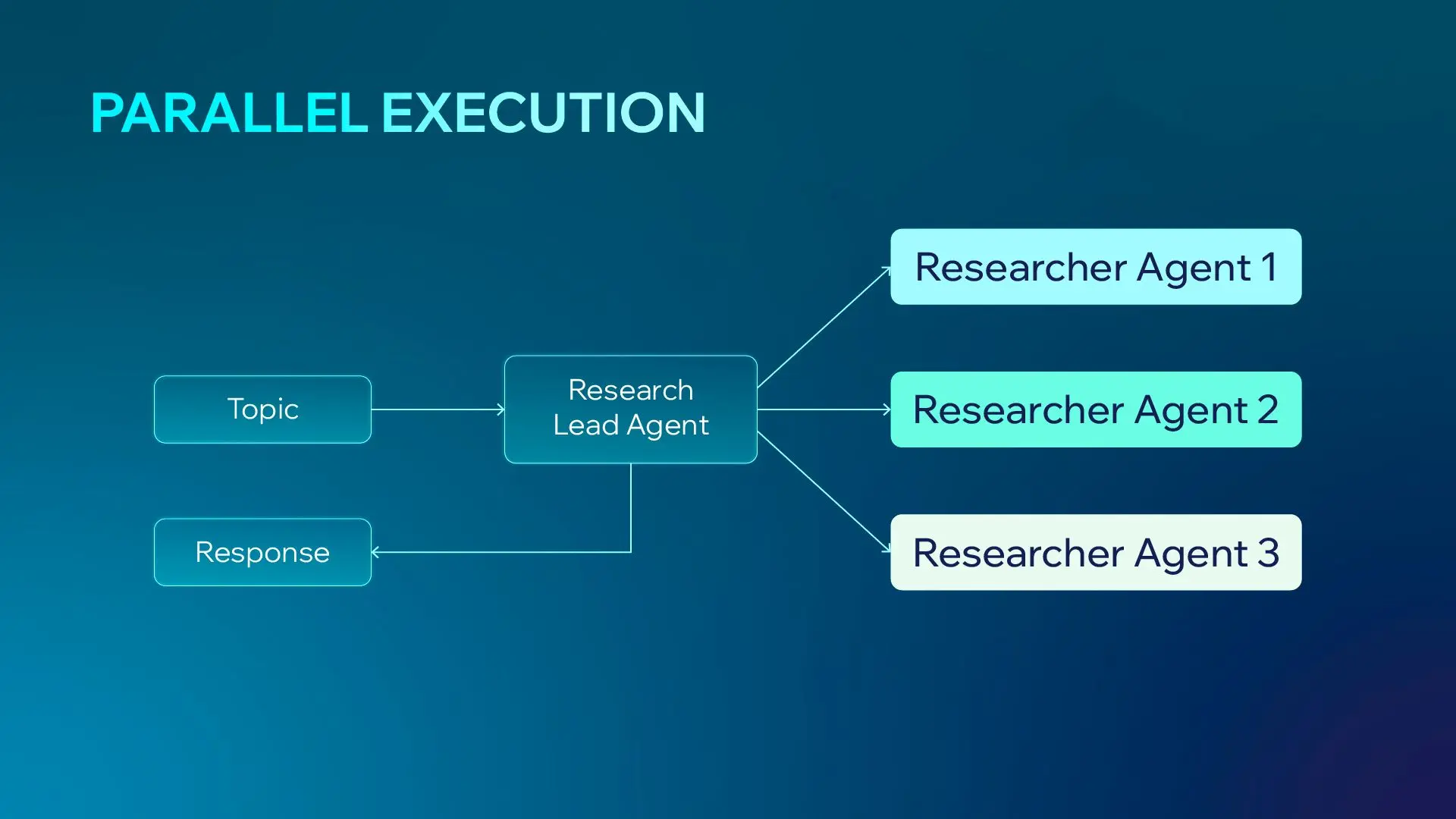
Parallelization in Multi-Agent Systems
In optimized multi-agent systems, parallel execution ensures total latency = slowest agent, instead of the sum of all processing steps.
Making Agents Smarter
Context Engineering > Prompt Engineering
While prompt engineering focuses on single-turn queries (few-shots, CoT, instructions), context engineering for AI agents determines system-level performance in real-world environments. It is an iterative curation phase where you decide exactly which tools, documentation, and message history to pass to the model at each step.
-
Context Rot is Real**:** As context windows grow, performance can decay. Optimization means not wasting tokens on low-signal data.
-
Hierarchy of Difficulty: Task performance is not linear. Retrieval is generally easier than reasoning or complex tool calling.
-
Difficulty Escalators: Agents become less reliable as you add "more needles" (specific facts), larger context sizes, more options, or more conversational turns.
Within a Single Agent
Optimization at the individual agent level focuses on reducing the search space and making the data LLM-friendly.
Context Compression
-
Lossy**:** Summarizing old turns or extracting only key facts while discarding conversational filler.
-
Lossless**:** Converting verbose formats like JSON into compressed text, YAML, or CSV to cut token usage
LLM-Friendly Patterns
Compress repeated data into references (e.g., "Dec 1-15: Sunny") to preserve information while minimizing token counts.

Reduce Task Difficulty
-
Instead of asking an agent to reason about a date like "yesterday," pre-process the data in code to provide an explicit reference (e.g., "Mon 23 - yesterday").
-
Just-in-Time Context: Filter data before the LLM sees it. For a weather query, send only the relevant day's data rather than a full 7-day forecast.
Among Multiple Agents
When a task is too complex for one model, AI agent optimization shifts toward multi-agent orchestration.
-
Why use Sub-agents?: They offer parallel execution and narrower scopes, which reduce decision fatigue and tool-choice errors.
-
Specialist vs. Generalist: Specialist agents with a focused toolset consistently outperform generalists on complex tasks.
-
The Consensus Model: Using a majority vote across multiple agents can exponentially increase reliability.
Conclusions
At the enterprise level, AI agent optimization is required to achieve predictable cost, performance, and scalability. Organizations that move beyond experimentation focus on structured architectures, governed context engineering, and measurable system outcomes.
This is what transforms AI from isolated experimentation into production-ready AI systems that deliver consistent, scalable business impact.
Marketing Team
Marketing






