Cost-optimized ML on production: Autoscaling GPU Nodes on Kubernetes to Zero using KEDA
Machine learning deployment reinvented: Autoscale GPU nodes on Kubernetes + KEDA for cost savings & peak performance!

Deploying a machine learning model can be very costly, especially when it requires a virtual machine with GPU (Graphics Processing Unit) cores that needs to run all day. GPU-based server prices can be a major pain point for developers and companies seeking to deploy their machine learning (ML) models. The cost of running the virtual machine, as well as the cost of the GPU, can add up quickly, even when the model is not being used.
Another common pain point is the lack of scalability. Virtual machines have a fixed amount of resources, which can limit your ability to handle sudden spikes in traffic. If your workload experiences a sudden increase in demand, you may need to spin up additional virtual machines to handle the load.
Doing this, however, can be time-consuming and expensive, especially if you need to do it quickly. You would need to provision the new virtual machines, configure them to work with your existing infrastructure, and make sure they have the necessary resources to handle the increased workload. Paying for these virtual machines can also drive up your costs.
In this article, we will explore how to address these problems by deploying a trained text-to-speech ML model using Kubernetes (K8s) and autoscaling GPU nodes from zero using Kubernetes Event-driven Autoscaling (KEDA). This approach can help significantly reduce costs while ensuring the model is available to handle requests whenever needed. We include examples and command samples you can use to start implementing this process yourself.
The approach to optimizing cost for machine learning models on production
The situation
If you're in a situation where you need to deploy a machine learning model that requires GPU cores, it's important to consider cost-effective solutions. One common approach that may come to mind is launching an instance 24/7. However, this approach may not be scalable and can lead to high costs.
Another option is using an auto-scaling group. These groups can launch instances when there are messages waiting in a queue, but scaling-in when there are no messages is complex due to an Amazon CloudWatch alarm only being able to reference one metric.
Although auto-scaling groups can be a useful solution, they may not work well for GPU-based models that require specialized resources. A solution to this problem is to use CPU-based cores with a fast serverless API that calls Python scripts for inference. However, if the model is GPU-based, a virtual machine with GPU cores is needed to run it.
If you have a client that calls the inference API periodically and ad-hoc, you'll need to run the inference daily for about 300 minutes of speech. While not huge traffic, it can still incur considerable costs due to the pricing of GPU-based servers. By considering different options and choosing the most cost-effective solution for your specific needs, you can deploy your machine learning model in a way that's efficient and effective.
The solution
After trying different approaches to address these pain points, we found the best solution is to use K8s and autoscaling GPU nodes to zero using KEDA. This approach can greatly cut costs while guaranteeing the model is always ready to fulfill queries.
One reason we chose this approach is that it provides a highly scalable and cost-effective solution. By using K8s to manage the deployment of the ML model, we can easily spin up and spin down resources as needed to handle fluctuations in traffic. Additionally, by using KEDA to manage autoscaling of GPU nodes to zero, we can ensure we only use resources when they’re needed, which can save costs.
While there are other alternatives available, we found that none of them provide the same level of cost and performance benefits as using K8s and KEDA. Within the scope of K8s, however, we found that we can replace KEDA with Knative, another open-source project, which provides similar benefits for managing autoscaling in a K8s environment.
K8s is an open-source container orchestration platform that allows developers to automate the deployment, scaling, and management of containerized applications. K8s provides a powerful set of tools for managing containers, including automatic scaling, rolling updates, and self-healing. By deploying the machine learning model using K8s, you can take advantage of these tools to reduce costs and improve scalability.
KEDA is an open-source project that allows K8s to scale workloads based on the number of events or messages in a message queue. KEDA can be used to autoscale K8s deployments, which are hosted on GPU nodes, based on the number of messages in a message queue.
By using KEDA, you can be sure the ML model is always available to handle requests, while also ensuring the GPU nodes are only active when needed.
The implementation
To implement this solution, you can create a K8s cluster using Google Kubernetes Engine (GKE). The K8s cluster should have two node pools. One node pool should be for the master nodes, which only need normal CPU machines. The other node pool should be for the GPU nodes that can scale up and down based on demand.
You can then deploy the ML model to the K8s cluster using a Docker image. The Docker image should include all the necessary dependencies, including the ML model and any Python scripts for inference.
To use KEDA create a Kubernetes Horizontal Pod Autoscaler (HPA) that targets the GPU node pool. GKE autoscaler will scale up GPU nodes when new Pods are requested.
Now, let's dive deeper into how to implement cost-optimized ML on production using autoscaling GPU nodes on K8s to zero using KEDA. This schema can help you visualize the process

How to create a Kubernetes cluster on GKE
The first step is to create a K8s cluster on GKE. We need to create two node pools - one for the master node and another for the GPU node. The master node can be a normal CPU machine, while the GPU node pool should have the appropriate GPU machine type. The GPU node pool should have a minimum of one node for the autoscaling to work correctly.
Run the following commands to create a GKE cluster with 2 node pools:
# Create cluster with default node pool and 2 CPU nodes
gcloud container clusters create cluster \
--machine-type=n1-standard-2 \
--num-nodes=2 \
--region=us-central1-c \
# Create autosale GPU node pool from 0 - 3
gcloud container node-pools create gpu-pool \
--cluster=ml-cluster \
--machine-type=n1-standard-2 \
--region=us-central1-c \
--spot \
--min-nodes=0 \
--max-nodes=3 \
--enable-autoscaling \
--accelerator=type=nvidia-tesla-t4,count=1
# Install Nvidia driver
kubectl apply -f https://raw.githubusercontent.com/GoogleCloudPlatform/container-engine-accelerators/master/nvidia-driver-installer/cos/daemonset-preloaded.yaml
Next, we need to install KEDA, an open-source component that enables automatic scaling of K8s workloads based on various triggers, including CPU utilization, message queue length, or custom metrics.
We can install KEDA by following the instructions from this post. Then, create a ScaledObject deployment and apply it to the cluster.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: ttsworker
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ttsworker
pollingInterval: 10 # Optional. Default: 30 seconds
maxReplicaCount: 5 # Optional. Default: 100
cooldownPeriod: 60
triggers:
- type: rabbitmq
metadata:
host: amqp://guest:guest@rabbitmq.rabbitmq:5672/
mode: QueueLength
value: "20"
queueName: tasks_queue
How to create a custom HPA
After installing KEDA, we need to create a custom HPA for our workload, which will be responsible for scaling up and down the (GPU targeted) Pod, then GPU nodes can be scaled by the cluster autoscaler accordingly with the Pod scale. We can specify the minimum and maximum number of replicas for the workload.
The HPA can be created using YAML files or K8s manifest files. We can use the KEDA CLI to generate the YAML files for the HPA, which makes the process simpler.
Once the HPA is created, we can deploy our workload, which is the text-to-speech ML model in this case. The workload can be deployed as a K8s deployment or a Kubernetes StatefulSet, depending on the application's requirements.
Technical details of an application
We use this technique for our text-to-speech API. The API will receive text in the request and then return an audio file in the response.
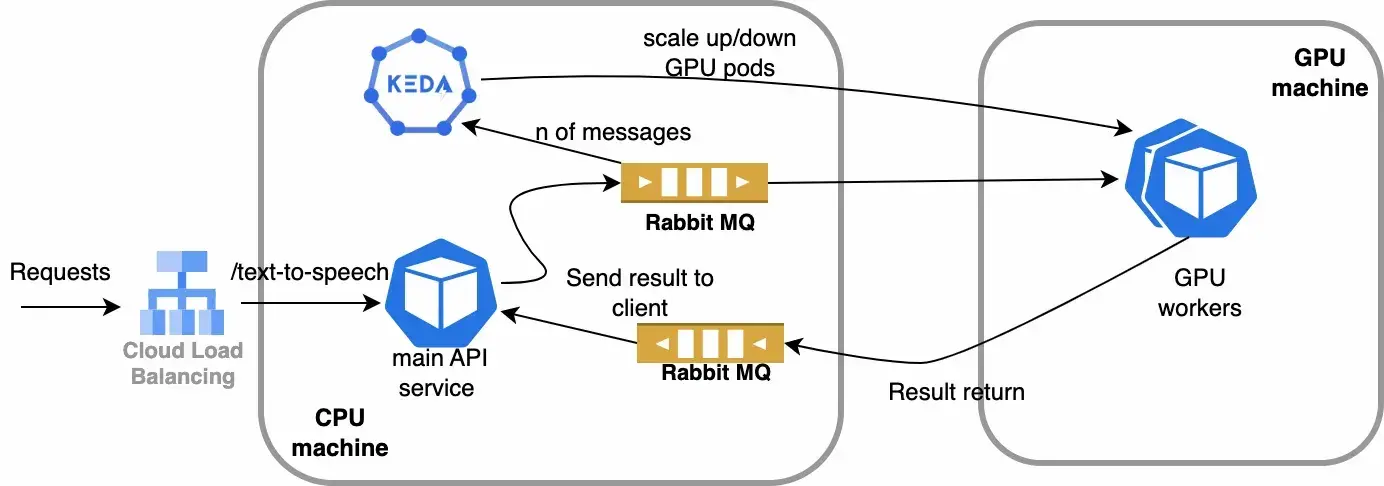
API server and GPU workers are Pod created in K8s cluster. The “API server” service which is a FastAPI server that receives FastAPI requests from the client then pushes the message to a RabbitMQ queue. The “GPU workers” receive messages from the queue then send it back to the “API server” through another queue. Depending on the number of messages in the queue, KEDA can scale the GPU workers up and down.
The pattern with 2 message queues for sending and receiving is called RPC (Remote Procedure Call). By using this pattern we can handle any online requests when and results are sent back to the client within the request life cycle.
It’s important to note there is a trade-off between cost and performance when using autoscaling GPU nodes. When the workload is triggered, there will be a delay before the GPU nodes are scaled up to handle the workload. This delay is due to the time required for the GPU nodes to start up and load the necessary ML model and libraries. Therefore, it is essential to factor in this delay when designing the workload and trigger frequency.
Cost structure
In us-central1 region
Option 1: dedicated server
For a VM with GPU
- VM n1-highmem-4: 4 vCPUs 26GB RAM $0.236606/h
- GPU T4: 16 GB RAM $0.35/h
- Total $0.236606 + $0.35 = $0.586606/h for a dedicated server
Estimate monthly cost: $422
Option 2: with our method
Price of the main node pool 2 x e2-medium : 2 x $0.033503 = $0.067
Price of a VM with GPU on demand VM n1-highmem-4 (spot): 4 vCPUs 26GB RAM $0.049812/h GPU T4 (spot): 16 GB RAM $0.11/h
Total (price per hour) $0.049812 + $0.11 = $0.159812 (on K8S cluster)
Estimated monthly cost Dedicated CPU nodes + On demand GPU node (2 hours every day) = 48 + 10 = $58
Here is a price structure for example, with the option 2 we can reduce the server cost by at least 5x
Conclusion
Cost-optimized ML on production can be achieved by autoscaling GPU nodes on K8s to zero using KEDA. By using this approach, we can save a lot of money while ensuring the ML model can handle the workload efficiently.
Although there is a trade-off between cost and performance, this approach is suitable for applications that have periodic or ad-hoc workloads and do not require continuous GPU resources. With the knowledge of K8s and KEDA, developers can leverage the benefits of autoscaling GPU nodes and optimize the cost of running ML models in production.
While not tested yet, the next step in this approach is to incorporate into any cloud (other than GCP) that has horizontal scaling. This is an exciting look into furthering this approach and seeing the additional optimizations that occur as a result.
Phong Nguyen
Technical Lead
Phong is a Technical Lead with over ten years of experience, including seven years dedicated to developing scalable AI systems. He specializes in Large Language Models (LLM), Natural Language Processing (NLP), and Computer Vision (CV), bridging technical complexities with strategy to drive impactful, data-driven solutions.






