Backend Engineering for Enterprise AI: What Engineering Teams Should Master
Enterprise AI needs more than strong models. This blog explains how backend engineering supports reliability, scalability, cost control, governance, and production readiness.

The role of AI Engineers has fundamentally evolved. The era of simply wrapping a generic API or training a standalone model in a Jupyter notebook is over. Today, enterprise competitive advantage lies in the ability to serve, integrate, orchestrate, monitor, and scale AI systems within complex, highly regulated enterprise environments.
For technology leaders, this shift changes what “AI capability” should mean inside an engineering team. A strong AI engineer not only understands model behavior, but also need to understand how that model becomes part of a reliable software system.
Here is the strategic backend architectural framework that technology leaders should expect from AI teams building production-ready systems.
1. APIs, Storage, and Databases
At its entry point, a foundational AI backend operates on traditional architectural patterns. A user or upstream service submits a request through an API, the backend processes the business logic, orchestrates calls to the model when necessary, persists relevant records, and returns the payload.
Without a strong backend foundation, even a capable model remains disconnected from the systems where business value is created.
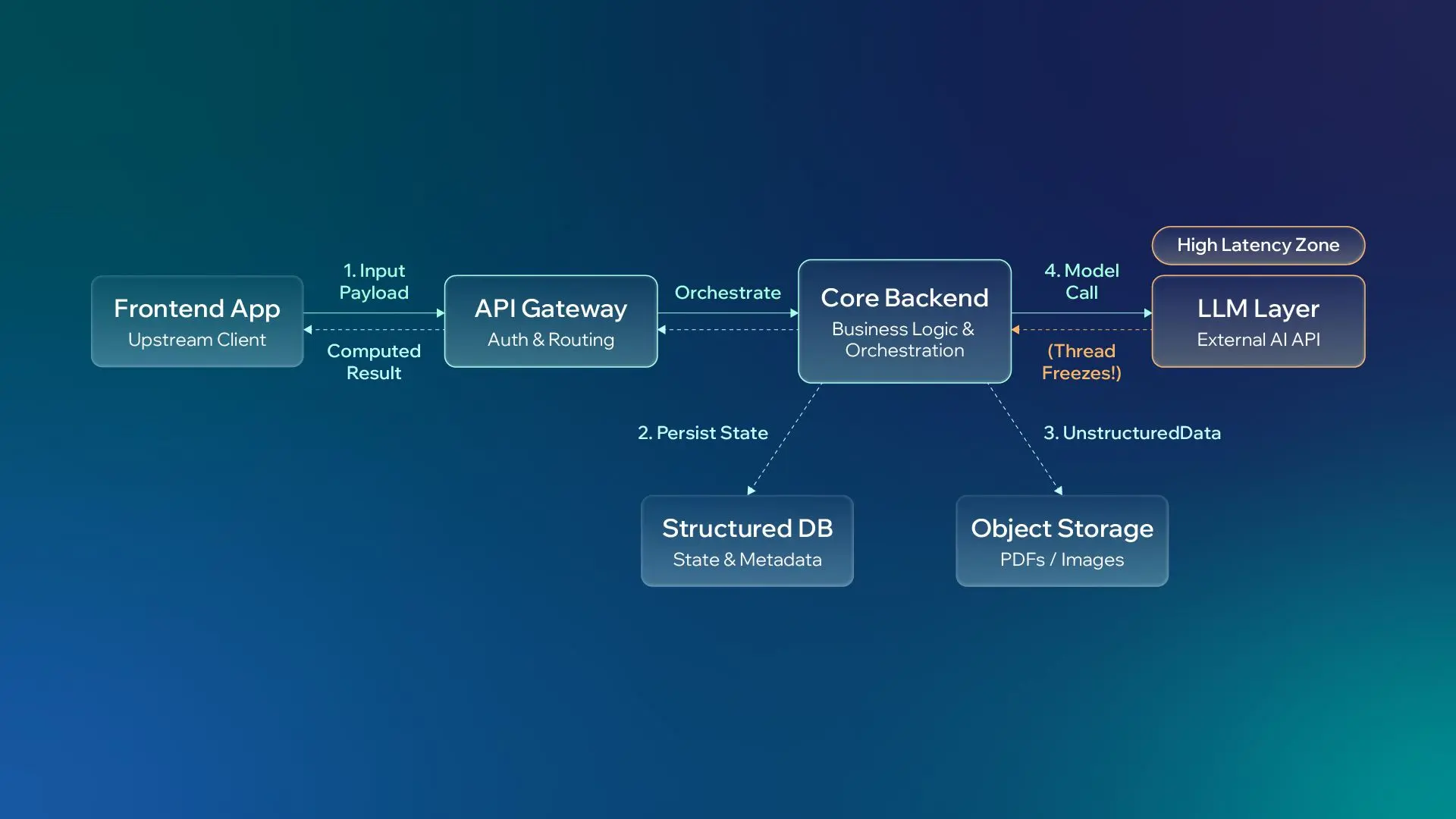
To establish this baseline, AI engineers need to master the fundamental data and ingestion layers:
-
API Gateways & Endpoints: Designing clean, secure interfaces to receive input and return model responses.
-
Unstructured Object Storage: Managing large-scale storage for files such as PDFs, images, documents, or uploaded corporate business records.
-
Structured Databases: Implementing robust data layers to persist user requests, transaction records, task metadata, and overall system state.
-
Enterprise API Documentation: Writing rigorous documentation so frontend teams, integration units, and external enterprise stakeholders can audit and interact with the system reliably.
The critical architectural risk appears when this baseline request-response setup is expected to survive enterprise workloads. When subjected to high-volume user traffic, long-running document processing, massive large language model (LLM) sequences, retrieval-augmented generation (RAG), or complex agentic workflows, a standard synchronous backend becomes a major production bottleneck.
Executive takeaway: APIs, storage, and databases are not just implementation details. They are the foundation for integration, auditability, data ownership, and enterprise-wide AI adoption.
2. Asynchronous Processing and Concurrency
Traditional software operations are fast and predictable, but AI workloads are inherently slow, variable, and compute-heavy. An LLM response may take several seconds, document extraction can take minutes, and a multi-step agent workflow might involve numerous tool executions, verification checks, and automated retries.
In a strict synchronous architecture, the system handles one execution flow from start to finish before moving on, creating avoidable idle time and constraining overall throughput. While a backend waits on a database query, a third-party API, a vector search, or a model generation step, it must not freeze.
In this case, asynchronous processing can decouple the request ingestion from execution, allowing the system to continuously receive inbound traffic while background workers manage long-running external dependencies.
For enterprise operations, mastering asynchronous architecture directly supports:
-
User Experience (SLA Adherence): The client interface remains responsive because the system does not freeze while waiting for heavy background tasks.
-
Resource Efficiency: Cloud compute and backend services maximize utility by handling other concurrent workloads during external network idle periods.
-
Horizontal Elasticity: Processing capacity can be scaled seamlessly across the infrastructure without requiring a top-down redesign of the application logic.
Executive takeaway: Asynchronous architecture protects responsiveness and SLA confidence when AI workloads become long-running, unpredictable, or compute-intensive.
3. Horizontal Scaling
AI applications often begin with a small group of internal users, then expand quickly once the business sees value. At scale, optimizing software concurrency via asynchronous code hits physical hardware limits. True enterprise volume requires infrastructural expansion, specifically Horizontal Scaling.
Rather than overloading a single server, horizontal sizing distributes the compute burden by running multiple identical backend instances behind a centralized load balancer. Traffic is intelligently routed across these distributed nodes, ensuring the application can support thousands of concurrent users while drastically reducing blast radiuses, ensuring that one overloaded service node cannot bring down the entire application.
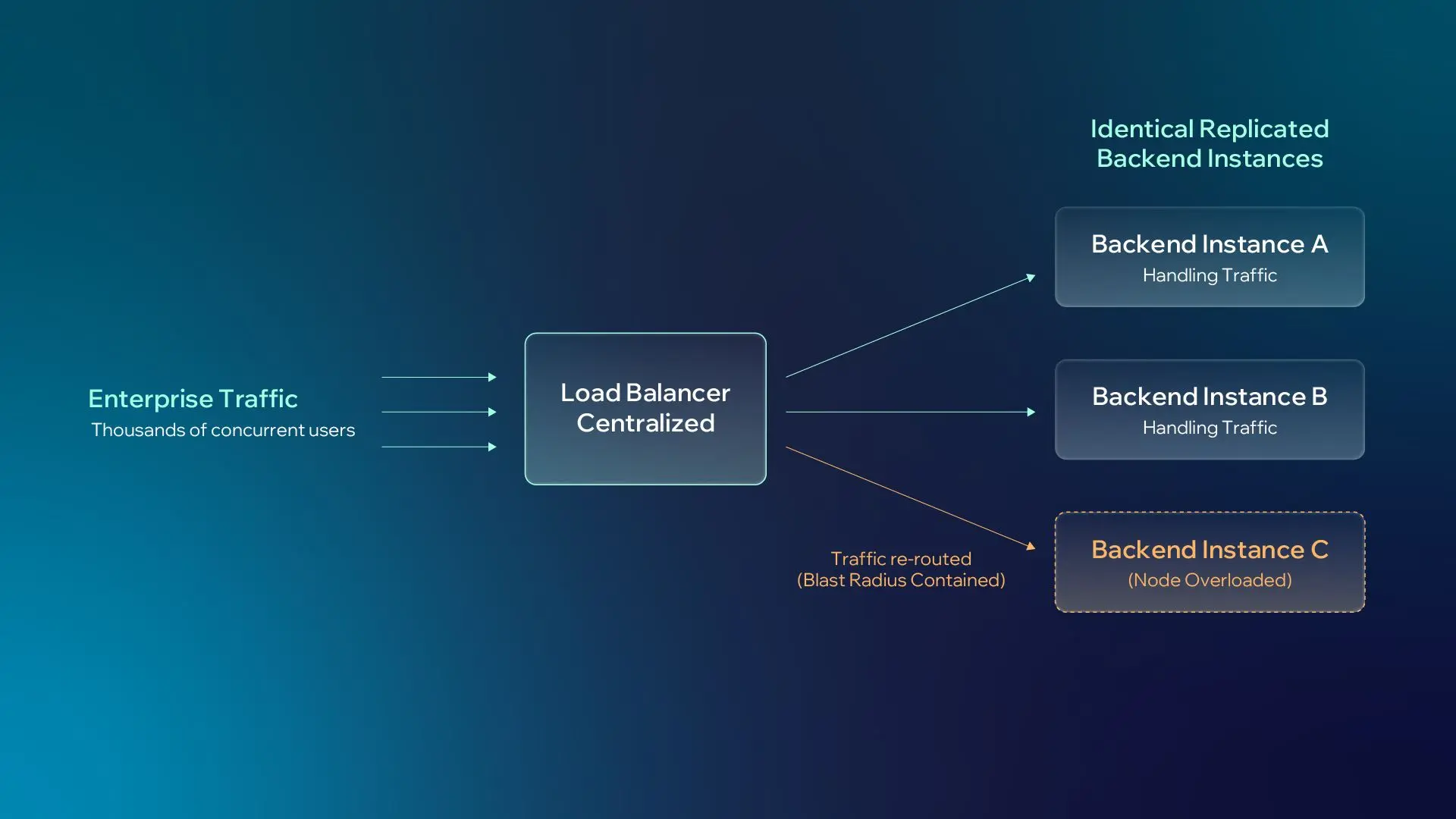
Executive takeaway: Horizontal scaling gives AI systems the capacity to grow with adoption while protecting availability, resilience, and business continuity.
4. Event-Driven Architecture (EDA)
As an enterprise AI ecosystem matures, deploying monolithic backend instances that attempt to execute every task becomes highly inefficient. It introduces severe resource contention, duplicated engineering effort, and unnecessary cloud expenditures.
At enterprise scale, AI systems need architectural specialization. Event-driven architecture (EDA) gives teams a practical way to separate request handling, workflow execution, status tracking, and result delivery.
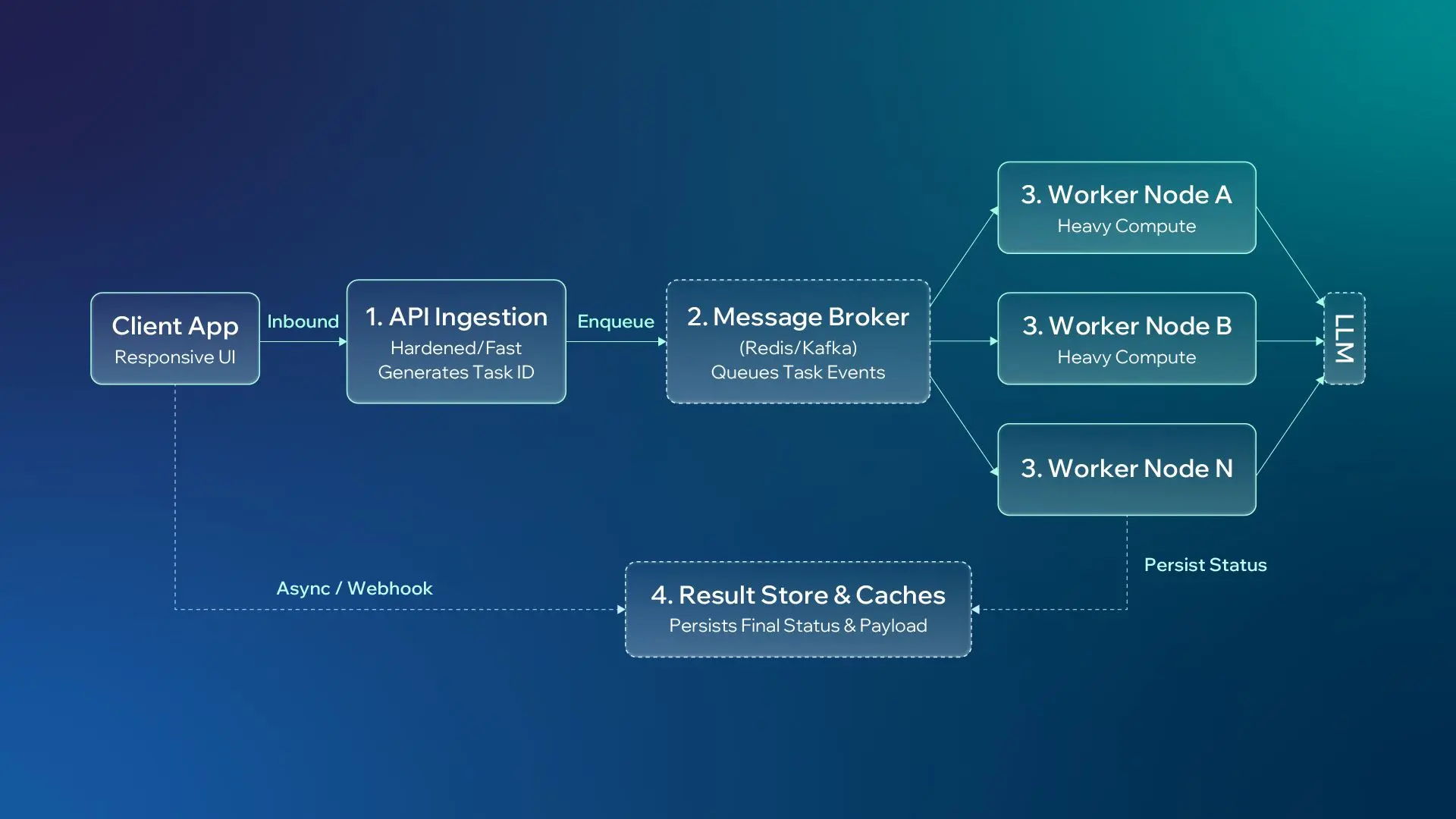
Instead of forcing a single monolithic service to receive a request, run the entire AI workflow, and return the final output, EDA cleanly isolates responsibilities into dedicated, specialized components:
-
API Ingestion Service: Dedicated solely to receiving user requests, validating inputs, handling authentication, generating a task event, and passing that event to a broker.
-
Distributed Message Brokers: Systems like Redis, RabbitMQ, or Apache Kafka that safely store, sequence, and distribute task events to available processing queues.
-
Worker Services: Headless compute instances optimized specifically to execute heavy business logic, downstream model calls, document processing, semantic retrieval, or multi-agent workflows.
-
Result Stores & Caches: Dedicated persistence layers that cache the final output and task status, allowing users to asynchronously poll or fetch results when ready.
This separation gives technology leaders more operational control. AI engineers can isolate request handling from heavy AI processing and scale each layer independently.
If user sign-ups surge, scale the lightweight API layer. If processing a multi-million token document workload bogs down the system, scale the worker pool without inflating the cost of the entire infrastructure.
Executive takeaway: Event-driven architecture gives leaders cost and capacity control because each part of the AI workflow can scale independently.
5. Distributed Retry Pipelines
In production environments, distributed failures are an absolute certainty. A model endpoint will timeout, a third-party API will rate-limit, a document parser will choke on an unmapped format, or a vector retrieval pipeline will return insufficient context.
A resilient, enterprise-grade AI system cannot afford to crash or blindly restart an entire multi-step workflow from scratch whenever a minor downstream dependency fails. Instead, the backend business logic must be divided into granular, deterministic checkpoints where the intermediate state is continually saved. This forms a robust Retry Pipeline.
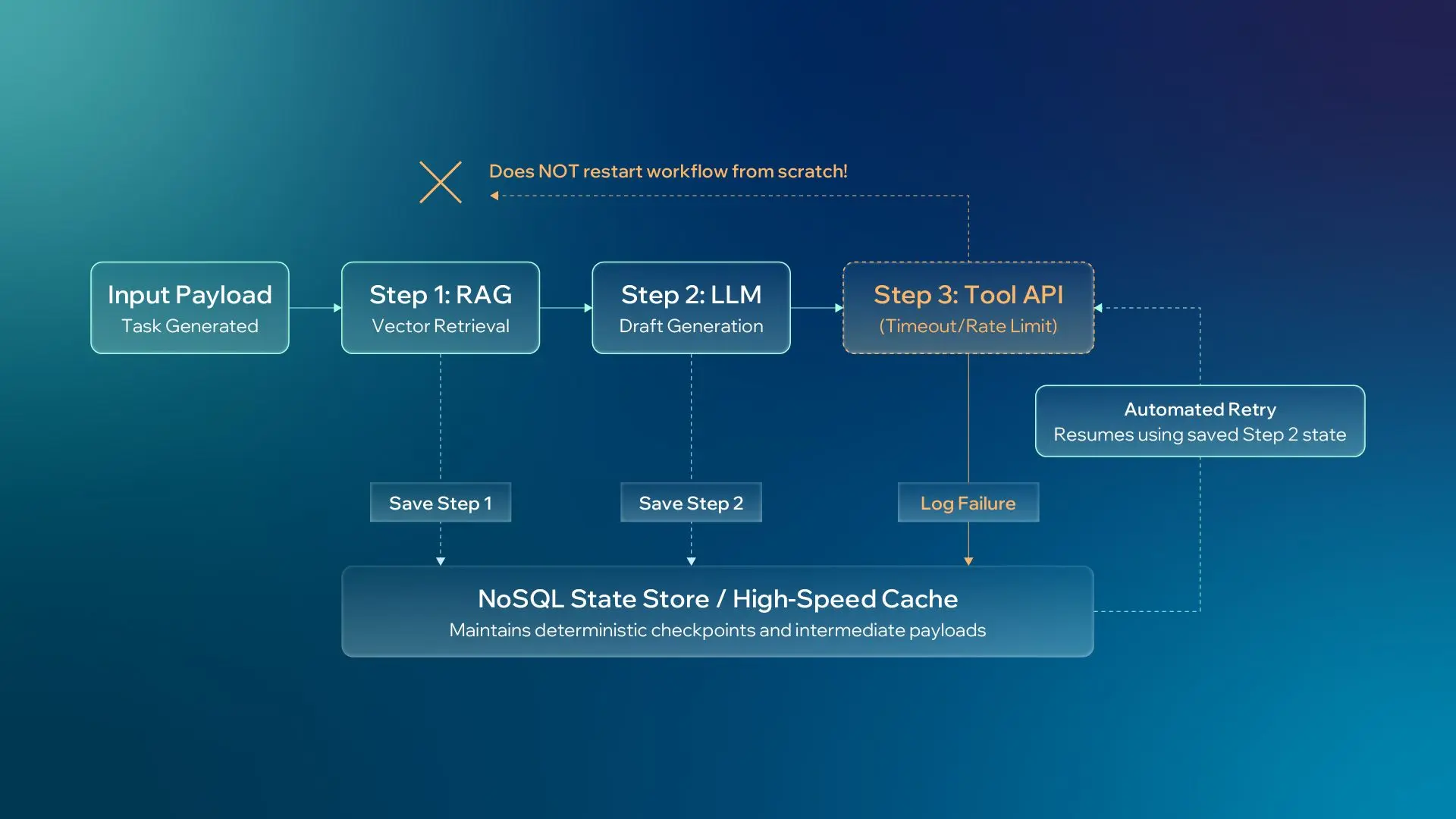
This level of fault tolerance guarantees three core outcomes:
-
Operational Resilience: recovering failures mid-stream without system crashes
-
Cost Control: preventing the re-billing of expensive tokens for steps already processed
-
Total Auditability: giving teams the precise telemetry to trace what went wrong, where it happened, and how the system recovered
Executive takeaway: Retry pipelines reduce downtime, protect AI operating costs, and give leadership the audit trail needed to trust production AI workflows.
6. Enterprise Caching Strategies
Inference costs and latency represent two aggressive barriers to scaling enterprise AI. Running a complete model workflow for every single inbound request is financially and operationally unsustainable.
When a backend system completes a processing chain, it should store the result in a high-speed caching tier (such as Redis). If a duplicate or semantically similar request is received, the backend bypasses downstream compute and instantly serves the cached result.
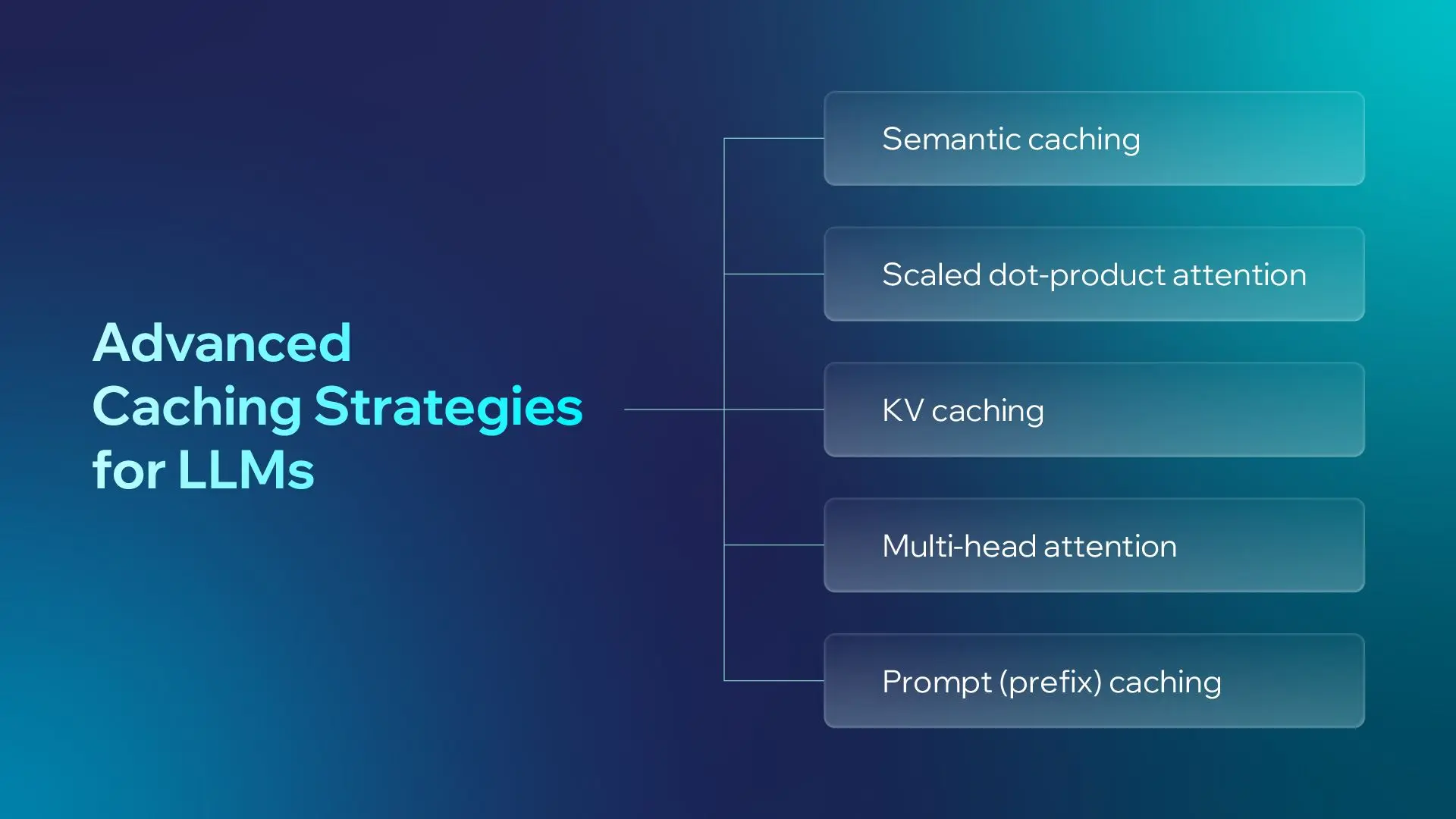
For enterprise deployments, an engineered caching strategy yields massive dividends:
-
Drastic Cost Reduction: Substantially lowers token spend and total cost of ownership (TCO) for LLM-reliant systems.
-
Sub-Second Response Times: Eliminates model inference latency for repeated queries.
-
Downstream Protection: Minimizes the computational load placed on worker pools and third-party model endpoints.
-
Predictable Performance: Smooths out system behavior and latency spikes during peak enterprise operational hours.
This is exceptionally vital for RAG, document analysis, repeated form processing, and internal corporate knowledge bases. Enterprise users frequently ask similar questions, analyze overlapping documents, or run identical workflows.
However, caching demands strict governance. The executive priority is ensuring AI teams can design caching layers that maximize performance without compromising corporate data privacy, accuracy, or regulatory compliance.
Executive takeaway: Caching is a performance and cost-control for AI systems operating at enterprise scale.
7. LLM Creativity and Generation
Many AI teams increase temperature when they want more creative LLM responses. This can make outputs more varied, but it is not the only lever, and it is often not the most reliable one for enterprise use cases.
LLMs generate responses by predicting the next token one step at a time. Before that happens, words are converted into embeddings: mathematical representations that place related meanings closer together in vector space. This is how the model understands that different words or phrases can point to similar concepts.
Temperature changes how broadly the model samples from possible next tokens:
-
Lower temperature: More predictable, consistent responses.
-
Higher temperature: More varied responses, but also higher risk of irrelevant or unstable output.
For enterprise AI systems, creativity should come from better system design, not just more randomness. Teams can improve creative quality through stronger context, clearer prompt structure, better retrieval, curated examples, and workflows that generate, compare, and refine multiple options.
Executive takeaway: Temperature can increase variation, but enterprise-grade creativity comes from better context, retrieval, and generation workflows. The goal is not random output. The goal is useful exploration within business constraints.
8. MLOps and Lifecycle Automation
Deploying an AI system is not a one-and-done software launch. Unlike traditional static code, machine learning systems degrade over time. Performance drifts as real-world user behavior shifts, foundational data evolves, underlying business rules change, and edge cases compound.
MLOps applies strict software engineering discipline to the entire machine learning lifecycle, ensuring AI engineers can seamlessly govern how data is handled, ingested, and deployed.
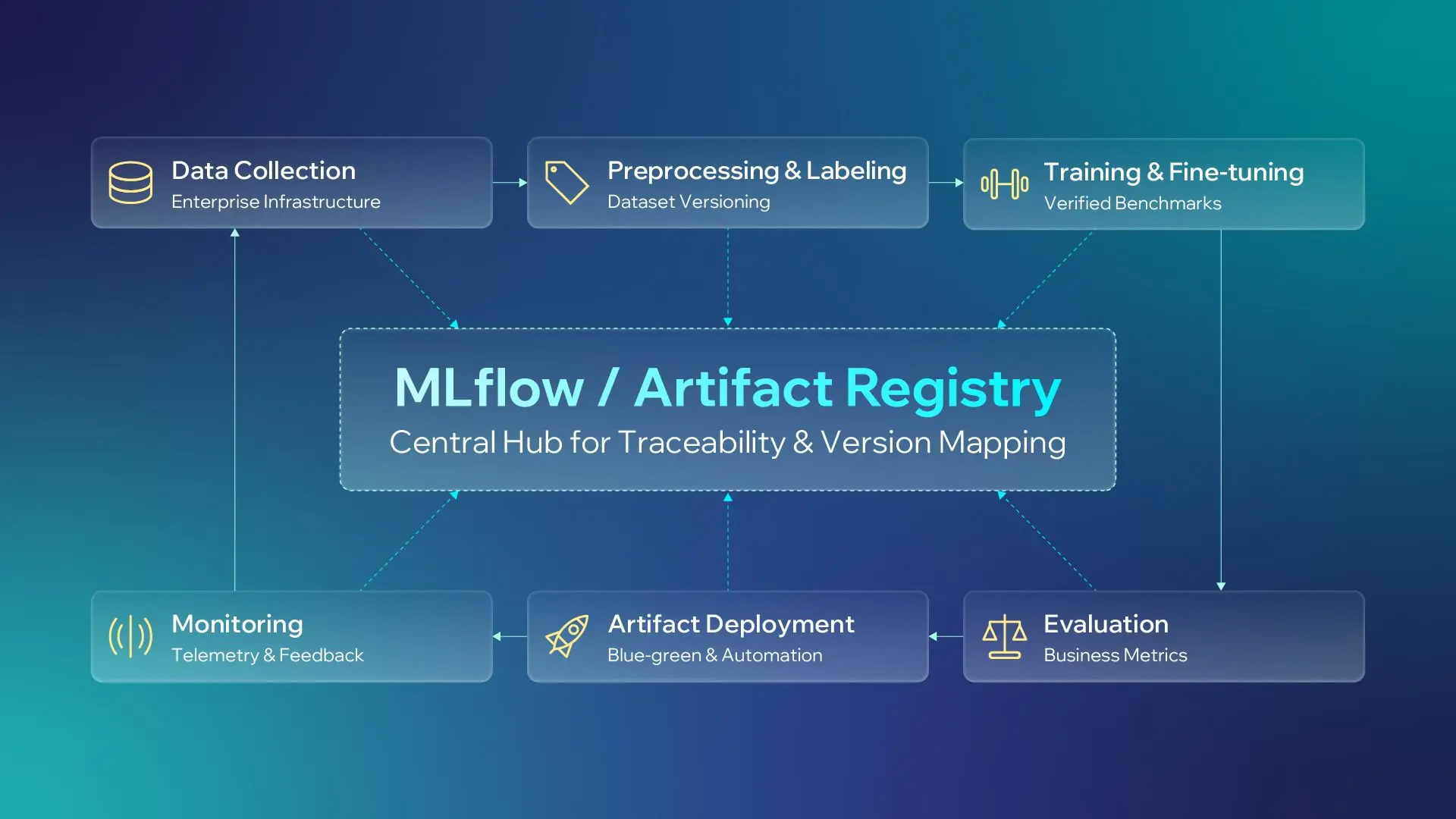
The overriding principle here is Traceability. If a newly deployed fine-tuned model begins underperforming or hallucinating in production, the organization must possess the tooling to instantly trace that failure back to the exact dataset version, hyperparameter configuration, evaluation benchmark, and deployment container utilized.
Executive takeaway: MLOps gives organizations release control, traceability, and accountability across the AI lifecycle.
9. LLM Guardrails
Non-deterministic model behavior creates security, compliance, and trust risks when AI systems move into enterprise workflows. Prompt tuning can improve response quality, but it cannot reliably prevent prompt injection, data exposure, hallucinations, or off-policy outputs on its own.
A production-ready AI backend needs guardrails that inspect both inputs and outputs before model behavior affects business systems.
Input Guardrails
Input guardrails reduce risks such as direct prompt injection, jailbreak attempts, indirect prompt injection, PII ingress, and denial-of-service attempts caused by oversized or malformed prompts.
-
Layer 1: Deterministic Sanitization
Applies hard length limits, Unicode normalization, hidden-character removal, and basic attack-pattern filtering before the prompt reaches the model. -
Layer 2: Semantic AI Classification
Uses fast, specialized security models to detect malicious intent, suspicious instructions, or policy-violating inputs that rule-based filters may miss. -
Layer 3: Tokenization and Masking
Detects and masks sensitive data, including PII, credentials, secrets, and regulated information, before model invocation. -
Layer 4: Structural Prompt Enclosure
Packages user input, retrieved context, system instructions, and constraints into clearly separated blocks so untrusted content is less likely to be treated as authoritative instruction.
Output Guardrails
Output guardrails reduce risks such as hallucinations, weak RAG faithfulness, IP leakage, source code exposure, PII exfiltration, syntax breakage, and off-brand responses.
-
Layer 1: Structural Compliance
Uses deterministic parsers to verify schemas, syntax, JSON structure, required fields, and workflow-specific formatting rules. -
Layer 2: Safety and Brand Alignment
Checks for unsafe content, toxicity, policy violations, tone issues, and misalignment with brand or domain expectations. -
Layer 3: Sensitive Data Leak Detection
Identifies restricted corporate data, personal information, credentials, proprietary code, or other sensitive content before the response is released. -
Layer 4: Truthfulness and Groundedness
Validates the response against retrieved context, approved sources, or business rules using NLI models, grounding checks, or fast LLM-as-a-judge evaluation.
Executive takeaway: LLM guardrails are the control layer that helps organizations secure infrastructure, protect sensitive data, and validate AI outputs before they enter business-critical workflows.
Conclusion: AI Engineering Is Now a Backend Discipline
The next phase of enterprise AI adoption will not be won by the organizations building flashy pilots or desktop demos. It will be won by those who can operate AI reliably, safely, and predictably in production under real-world enterprise conditions.
That is why backend engineering is no longer an optional skill set for AI teams, but a foundational requirement. It gives leaders the foundation to scale adoption, manage risk, control cost, and move from isolated experiments to production systems that create measurable business value.
Quang Hong Nguyen
AI Engineer
Quang is a skilled Backend & AI Engineer with over 3 years of experience across various technologies. He has deep expertise in Computer Vision, Convolutional Neural Networks (CNN), and Transformer models, with hands-on experience in Large Language Models (LLMs) and related techniques. Beyond AI, he is proficient in backend development, designing and optimizing scalable systems, and deploying AI models efficiently on Azure Cloud.




